之后准备学习混淆和反混淆,于是查阅了一些 paper,然后根据自己的理解简单总结了一下,画了一张思维导图。
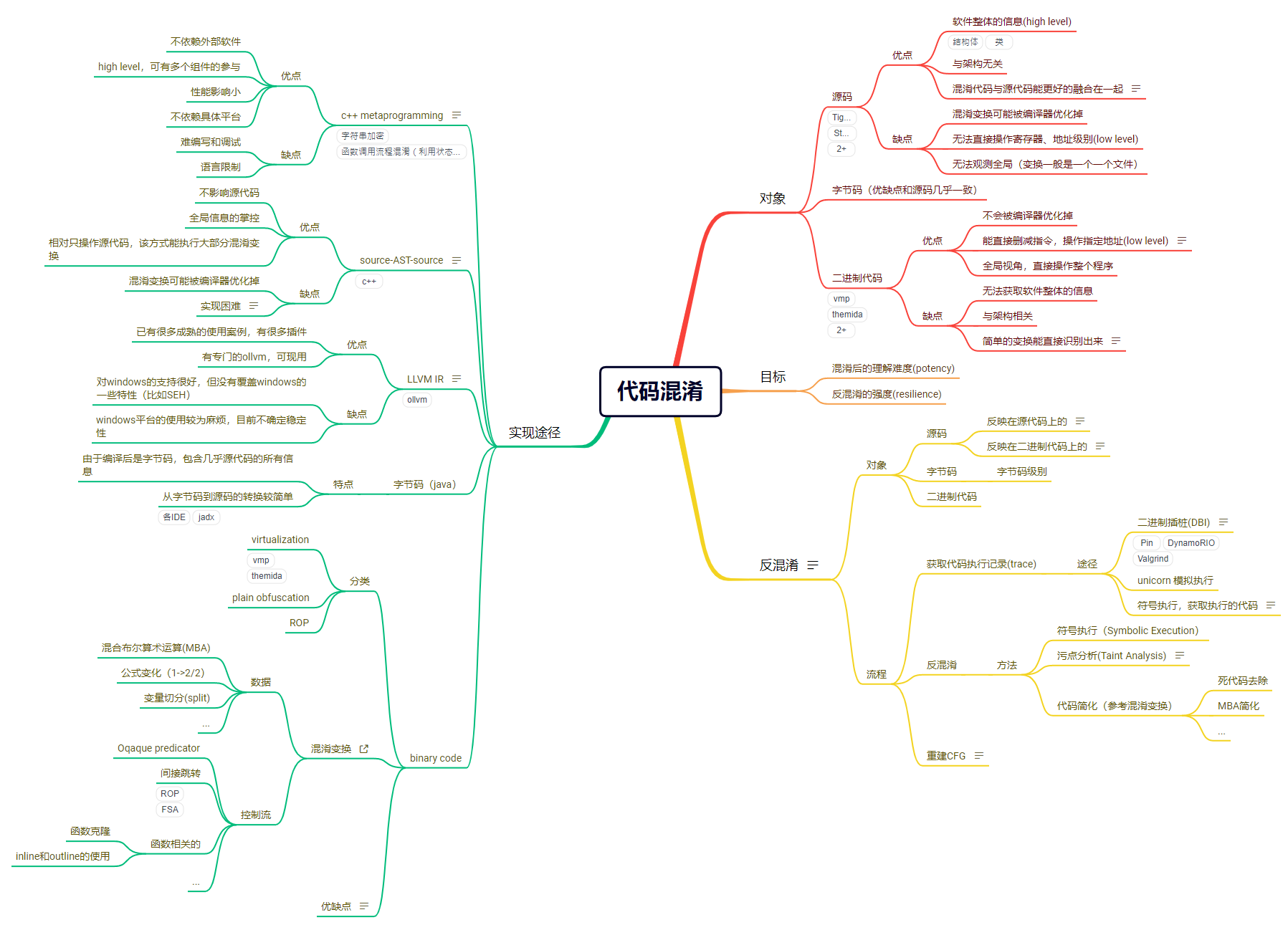
# 混淆的意义
混淆的意义在于保护产品,其作用在于增加逆向分析者的分析成本。
# 混淆的分类
# 源码混淆
由源代码转换到混淆后的源代码。
# 作用
脚本、解释型语言(比如 PowerShell)
混淆源代码(变量重命名等),降低可读性。
powershell 混淆原理可参考:Powershell 代码反混淆技术研究
编译型语言(比如 C++)
混淆源代码,降低可读性(针对源代码要提交给第三方的情况,编译出的二进制与未混淆没有区别),
工具举例:Stunnix,这种与 powershell 类似,因此不做细节讨论。
给原程序逻辑添加控制流混淆、添加 opaque predicate 等(未找到开源工具),增加逆向难度。
# 优缺点
参考思维导图。
# 实现
将源代码解析为 AST(Abstract Syntax Tree),执行混淆变换(Transformation),最后渲染(Render),转换成源代码。
# 限制
- 脚本 \ 解释型语言:该方法已被广泛运用,并无限制
- 编译型语言:
- 混淆源代码的方式(变量名替换、常量替换成复杂的公式),没有限制
- 添加混淆逻辑的方式,没有成熟的使用案例,仅在 paper 中找到了样本原型 (prototype),似乎源码也没有
- c++ 的混淆实现可参考:Code Obfuscation for the C/C++ Language
- 源代码的混淆实现可参考:On the Effectiveness of Source Code Transformations for Binary
Obfuscation
# 字节码混淆
将源代码编译生成的字节码转换成混淆后的字节码,最后交由解释器执行。
# 作用
保护编译生成的字节码(比如 java),字节码几乎包含源码的所有信息,因此需要混淆逻辑,降低代码的可阅读
性、提高反混淆的难度。
# 优缺点
参考思维导图。
# 实现
将字节码解析成 AST 或其他可解析的形式,执行混淆变换,最后渲染(Render),输出混淆后的源代码。
java 字节码的混淆可参考:A Taxonomy of Obfuscating Transformations
# 二进制代码混淆
将可执行程序的二进制代码转换成混淆后的二进制代码。
# 作用
增加二进制代码逆向阅读的难度。
# 优缺点
参考思维导图。
# 实现
- 代码虚拟化,将代码转换成另一套表示,并按特定语义解释执行
- 反汇编二进制代码,根据二进制代码的某些特征,执行对应的混淆变换
二进制代码的混淆可参考:Writing a Mutation Engine and breaking Aimware
# c++ 元编程 (metaprogramming)
添加保护接口,对使用这些接口的字符串和函数进行保护。
# 作用
利用 C++ 的模版特性(编译时)和状态机,实现代码保护,比如字符串加密、函数调用隐藏。
# 限制
仅适用于使用 c 语言,且支持 c11 及以上版本。
- c++ 元编程的混淆可参考:C++11 metaprogramming applied to software obfuscation
- 开源项目可参考:ADVobfuscator
# 代码混淆方法
不管是哪一类代码混淆,使用的混淆变换(Obfuscation Tansformation)都是适用的。
代码混淆的通用方法可参考:A Taxonomy of Obfuscating Transformations
这里不涉及二进制代码的混淆方法
# 控制流混淆
修改原有程序的控制流,或者在原有程序的控制流上添加假的控制流 (opaque predicate)。
# Opaque Predicate
可理解为一个返回 bool 类型的函数。混淆时返回结果已知,在代码运行时需要一定的计算才能知道返回结果。
该函数的重点在于构造一个适宜计算难度的公式,使得逆向分析人员难以阅读,编译器无法优化掉,使源程序的
控制流更加复杂。
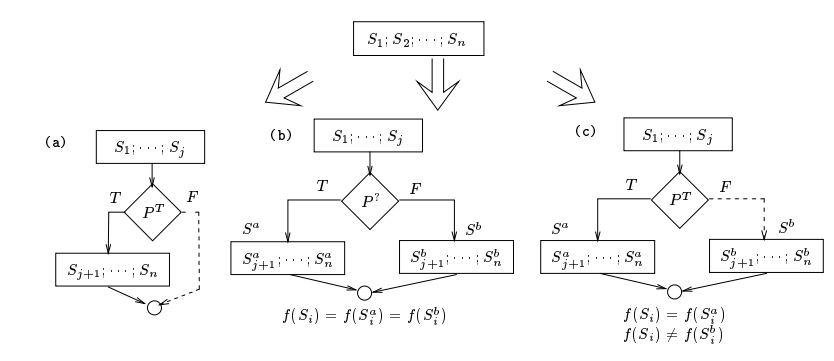
# Computation 变换 (举例)
插入死代码或不相关的代码
![image-20221103134641581]()
给定一个顺序执行序列,S1 到 Sn:
a) 添加一个 opaque predicate (T),由于该 predicate 恒为 true,所以只会走左边。
b) 添加一个 opaque predicate (?),该 predicate 返回值未知,但左右边代码一致。
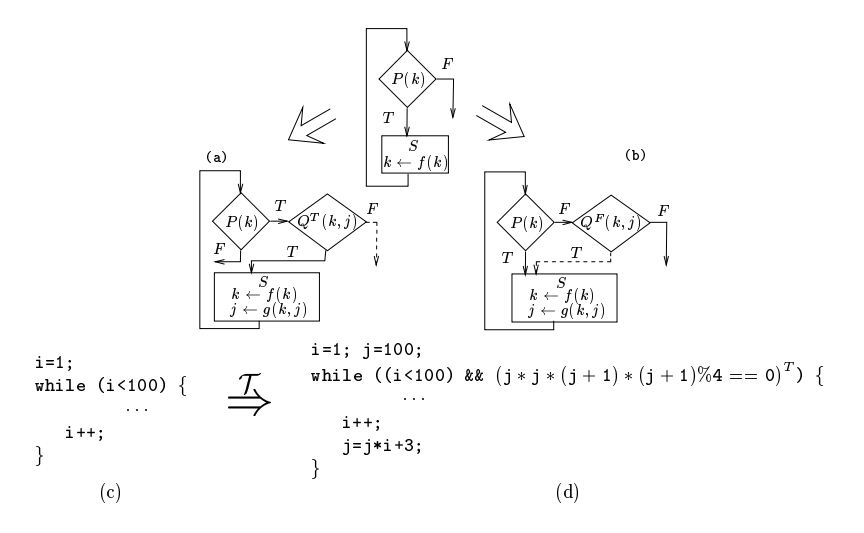
c) 添加一个 opaque predicate (T),想对于 b),右边的 S (b) 序列添加了 bug。混淆 Loop 控制流
![image-20221103134701976]()
添加一个 opaque predicate (T),不影响流程,但是使得流程复杂了。
可以将循环的执行体拆分为多个部分,在这些部分中穿插 opaque predicate (F),增加控制流的复杂度。
# 数据混淆
# Data 变换(举例)
变量表示
![image-20221103135055555]()
将 i 转换成 c1*i + c2 形式(简单例子,通常有更复杂的)。
变量拆分(split)
![image-20221103135137655]()
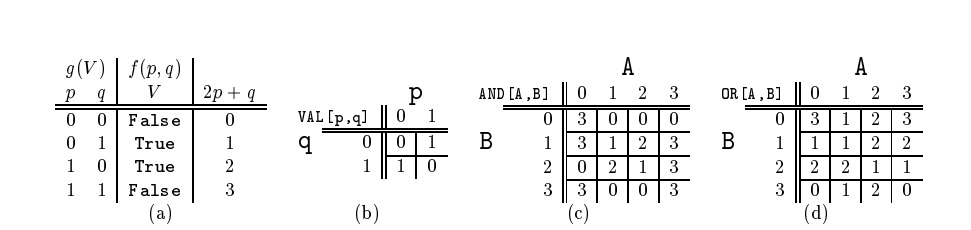
以布尔变量为例,将布尔变量拆分为两个变量 p 和 q,通过 2p + q 的方式来代表布尔变量。真实使用时如下:
![image-20221103135158027]()
布尔变量的定义改成 p 和 q 变量的定义,布尔变量的位运算交给 AND 和 OR 函数。
变量整合 (merge)
![image-20221103135215506]()
将类型为 int 的 X 和 Y 变量转换成类型为 long 的 Z,执行对应的公式计算。
数据拆分与整合
...
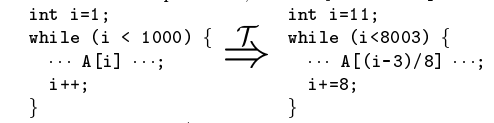

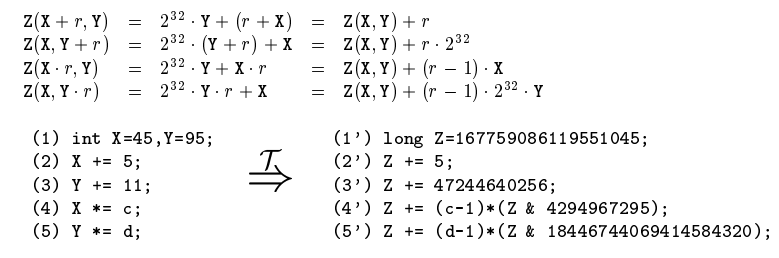
# 反反混淆
# Opaque Predicates
- 复杂度选择
- 别名 (alias) 的应用
- inter-procedual 的构造方法(predicate 涉及的变量(公式)在不同地方被更新)
- 使用有关联的 opaque predicates
- 使用 P (?),而不是简单的 P (F) 或者 P (T)
- 反程序切片技术 (program-slicing),比如增加切片大小(增加变量的依赖变量)
# 反混淆
# 分析记录的代码 (trace)
通过动态二进制插桩或者 unicorn 模拟获取 trace 代码
分析 trace
构造 CFG(control flow graph),消除多余的代码
- 使用常用的编译优化方法,比如常量折叠 (constant folding),消除共同子表达式 (common
subexpression) 等 - 定位 opaque predicates,对简单的 predicates 使用模式匹配去掉(结合符号执行)
- 对于数据变换这一类混淆,简单的情况下也可使用模式匹配;复杂的情况一般都需要具体分析(比如变
量拆分这种) - 其他的各种优化(程序切片,污点分析...)
- 使用常用的编译优化方法,比如常量折叠 (constant folding),消除共同子表达式 (common
根据优化后的 trace,重构 CFG,分析优化的代码
注:一般的编译器优化可以借用 LLVM 的编译器优化实现。(比如将汇编代码转成 LLVM IR、再编译成可执
行文件,之后用 IDA 等工具再进行分析)反混淆案例可参考:
https://github.com/JonathanSalwan/VMProtect-devirtualization
https://bbs.pediy.com/thread-273830.htm
https://bbs.pediy.com/thread-267741.htm
# 动态符号执行(Symbolic Execution)
通过符号执行,尽可能获取所有 path 对应的 trace,针对这些 trace 再进行上一小节的优化。
- 由于符号执行会有路径爆炸等问题,针对路径少、混淆程度轻的程序,该方法适用。
- 该方法可参考 ollvm 的反混淆入门:Deobfuscation: recovering an OLLVM-protected program
# 污点分析 + 动态符号执行
给一个特定输入,记录 trace,通过污点分析得到相关指令,符号执行该 trace 得出下一个输入(不同路径);然
后循环上述方式,整合所有输入,重构 CFG。
该方法可参考:Symbolic deobfuscation: from virtualized code back to the original
# 附录
比较有参考价值的 paper 放在 seafile 的 JJDPS\ 混淆调研 \ 资料目录下。
