# 本文目的
在用 Windows 平台使用 qiling 模拟执行框架中遇到了诸多困难,有些问题并没有查询到解决办法,于是记录此篇文章,希望能给到大家一些参考。
以下列举了本文想阐述的内容点:
- aarch64 so 基于 qiling 如何做模拟执行
- Windows 上使用 qiling 的一些问题解决
- 算法中虚拟机的模拟执行
本文尽可能从初学者的视角来阐述,初学者可以自行实践。
# 分析目标
最近需要分析一个 libxx.so 的加密算法,发现是 aarch64 的 so,于是有以下三个思路
- 用 IDA 静态分析
- 用调试器调试,跟踪算法流程
- 用 unidbg、unicorn 做模拟执行
# 选择模拟执行的原因
# 静态分析成本过高
用 IDA 看了一下加密函数,有点像嵌套的控制流平坦化,但实际上是一个虚拟机,这样静态分析的难度就提升了不少。
# 用调试器调试
最初的想法是编译一个 ARM64 的可执行文件,然后加载 libxx.so,调用加密函数来调试。通过 IDA 查看字符串信息,发现是 ndk+llvm 编译的 so,给安卓平台使用的。于是想安装一个 ARM64 的 ubuntu 虚拟机来调试,但 ubuntu 似乎没提供 ARM64 的客户机,只有服务端版本。可能准备其他发行版本的 linux(比如 centos)可以调试,但想到模拟执行在 trace 等功能相较于调试器会更好用点,所以最后选择了用模拟器的方式。
现在想来,可能用 Android Studio 写个 app,然后用 lldb 来调试可能是最稳定的调试方式。大家有什么其他好的意见呢?
# 模拟执行
unidbg 基于 unicorn,可以模拟执行安卓的 so,能很好的满足需求。但从 Bet4 的这篇文章中,unidbg 也存在模拟缺陷,于是我选择了 qiling 作为模拟执行框架,详细理由可参考上文提及的 Bet4 的文章。
从官方文档了解 qiling 的大致使用方法后,发现 qiling 有自带的 qdb 调试器,不过不支持多线程,而 Bet4 开源的 udbserver 支持多线程,配合 pwndbg 效果图如下(图来自 Bet4 的帖子):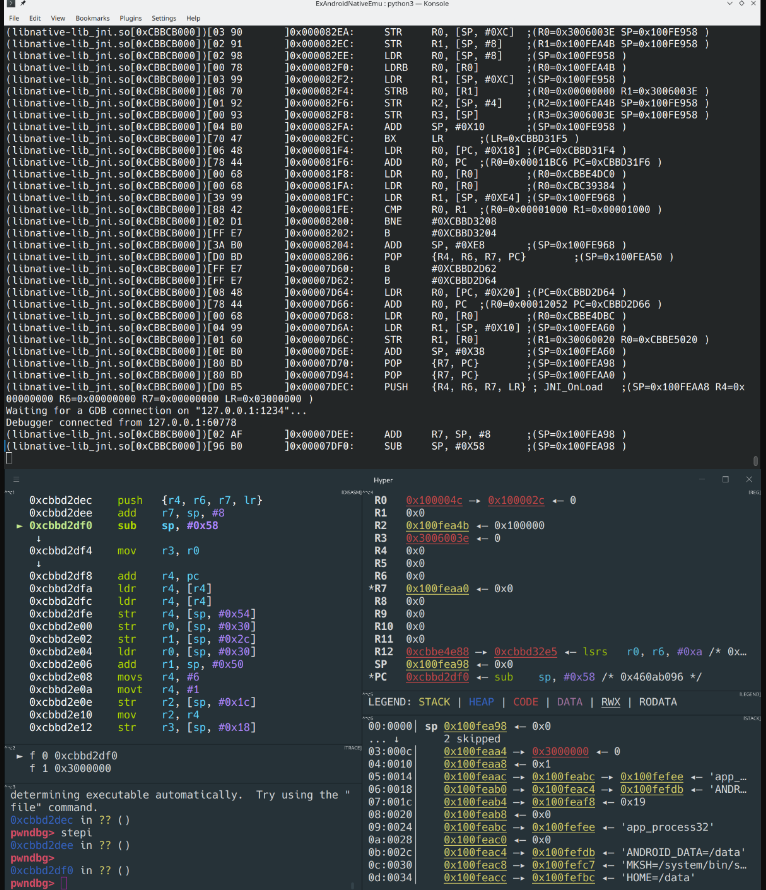
之后又发现 qiling 提供了 IDA 插件,方便直接在 IDA 中模拟执行 so。因为分析算法会经常参考 IDA 的一些视图,如果用 udbserver 的话,会在 gdb 调试器和 IDA 之间频繁切换,最后我选择使用 qiling 的 IDA 插件来 “可视化地调试 so”。
# ARM64 demo 运行
在 qiling 源码的 examples\rootfs\arm64_linux\bin 目录下,有很多 arm64 程序可供模拟执行,lib 目录下包含了程序对应的动态链接器,ARM64 对应的动态链接器一般是 ld-linux-aarch64.so.1。这个动态链接器非常关键,它负责程序依赖的库的加载和程序自身的重定位等功能。
接下来拿 bin 目录下的 arm64_hello 举例,演示如何用 IDA 插件来模拟执行一个 aarch64 的 so,arm64_hello 的功能是输出 “Hello, World!” 字符串,然后退出。官网的完整 demo 可查看这个链接。
# 初始化 qiling 环境
用 IDA 加载 arm64_hello,选择 "File->Script file..." 加载 qiling\extensions\idaplugin\qilingida.py。
在我的电脑上软连接无法生效,可能 qiling 只测试了 Linux,所以这里直接用 IDA 加载脚本的方式来加载 qilingida.py。
然后在 IDA 汇编视图右键 ->Qiling Emulator->Setup(后续简称 Qiling-> ),加载 IDA 插件,这里使用 qiling 默认的辅助脚本(custom_script.py)。在 IDA 中的一些自动化逻辑都可以放到该脚本中,比如添加一些 syscall 或者针对某地址的 hook 到该辅助脚本,之后会举例脚本的用法。

俗话说万事开头难,运行 demo 就出现加载失败了,如下:
File "C:\Program Files\Python39\lib\site-packages\qiling\os\linux\linux.py", line 30, in __init__
super(QlOsLinux, self).__init__(ql)
File "C:\Program Files\Python39\lib\site-packages\qiling\os\posix\posix.py", line 190, in __init__
super().__init__(ql)
File "C:\Program Files\Python39\lib\site-packages\qiling\os\os.py", line 63, in __init__
sys.stdin.fileno()
AttributeError: 'NoneType' object has no attribute 'fileno'
观察 os.py 的源码:
try: | |
# Qiling may be used on interactive shells (ex: IDLE) or embedded python | |
# interpreters (ex: IDA Python). such environments use their own version | |
# for the standard streams which usually do not support certain operations, | |
# such as fileno(). here we use this to determine how we are going to use | |
# the environment standard streams | |
sys.stdin.fileno() | |
except UnsupportedOperation: | |
# Qiling is used on an interactive shell or embedded python interpreter. | |
# if the internal stream buffer is accessible, we should use it | |
self._stdin = getattr(sys.stdin, 'buffer', sys.stdin) | |
self._stdout = getattr(sys.stdout, 'buffer', sys.stdout) | |
self._stderr = getattr(sys.stderr, 'buffer', sys.stderr) |
报错提示 sys.stdin 为 None,这是因为 IDA 修改了 sys.stdin,使用了自己的输入输出流。这个问题在 qiling 的 github issues,pull request 都有提到,我这里直接捕获 AttributeError 异常,如下:
except (UnsupportedOperation, AttributeError): |
修复之后,重启 IDA 加载 qiling 环境(python 安装的 qiling 环境),Qiling->Setup,报错如下:
这里修复的 os.py 文件是 python 库下的 qiling,也就是 C:\Program Files\Python39\lib\site-packages\qiling\os\os.py。
File "E:\gitRepo\qiling\examples\extensions\idaplugin\custom_script.py", line 1, in <module>
from future import __annotations__
ImportError: cannot import name '__annotations__' from 'future' (C:\Program Files\Python39\lib\site-packages\future\__init__.py)
[INFO][(unknown file):0] Custom user script not found.
这里我使用的 python 版本是 3.9.13,大致查了一下,python 库有__future__,没有 future,不知道与 python 版本是否有关,改成如下形式,再次加载就成功了。
from __future__ import annotations |
# 开始模拟执行
现在,arm64_hello 已加载进内存,动态链接器需要修复重定位表、设置程序入口点等,然后开始运行。
阅读 qiling\os\linux.py 的 QlOsLinux::run 方法,由于当前是单线程环境,且没有显式指定运行的起始地址,因此程序的起始地址是动态链接器的入口点,待动态链接器初始化后,将跳转到程序的真正入口点:
# 如果是一段二进制代码# 如果是多线程环境# start multithreading# 不是多线程环境# 程序入口点是否有显式指定# do we have an interp?# start running interp, but stop when elf entry point is reached
IDA 汇编视图右键 ->Qiling Emulator->Continue 开始模拟执行,报错:
[+] brk: increasing program break from 0x555555568000 to 0x555555589000 | |
[+] 0x00007fffb7e9e93c: brk(inp = 0x555555589000) = 0x555555589000 | |
[+] Received interrupt: 0x2 | |
[+] write() CONTENT: b'Hello, World!\n' | |
[x] Syscall ERROR: ql_syscall_write DEBUG: A string expected | |
Traceback (most recent call last): | |
... | |
File "C:\Program Files\Python39\lib\site-packages\qiling\os\posix\syscall\unistd.py", line 410, in ql_syscall_write | |
f.write(data) | |
File "D:\Tools\IDA 7.5\python\3\init.py", line 63, in write | |
ida_kernwin.msg(text) | |
File "D:\Tools\IDA 7.5\python\3\ida_kernwin.py", line 236, in msg | |
return _ida_kernwin.msg(*args) | |
TypeError: A string expected |
这里看到已经成功执行 puts 函数,打印了 “Hello, World”,当把这个字符串传给 python 打印时,出现异常,原因是 qiling 传给 ida_kernwin.msg 方法的类型是字节字符串,不是字符串。
解决办法有两个:
- 直接改 D:\Tools\IDA 7.5\python\3\ida_kernwin.py 的源码,兼容字节字符串
- hook write 函数,替换掉 qiling 自己的 ql_syscall_write
第一种方法由于是全局的,会影响到其他二进制文件的分析,且 hook 系统函数是 qiling 自身的功能,所以使用第二种方法。
修改 custom_script.py,如下:
def my_syscall_write(ql: Qiling, fd: int, buf: int, count: int): | |
ql.log.info('my_syscall_write called') | |
try: | |
# read data from emulated memory | |
data = ql.mem.read(buf, count) | |
# select the emulated file object that corresponds to the requested | |
# file descriptor | |
fobj = ql.os.fd[fd] | |
if fobj == None: | |
ql.log.ingo('none file descriptor') | |
# write the data into the file object, if it supports write operations | |
elif hasattr(fobj, 'write'): | |
fobj.write(data.decode('utf-8')) | |
except: | |
ret = -1 | |
else: | |
ret = count | |
ql.log.info(f'my_syscall_write({fd}, {buf:#x}, {count}) = {ret}') | |
return ret | |
class QILING_IDA: | |
def _show_context(self, ql: Qiling): | |
registers = tuple(ql.arch.regs.register_mapping.keys()) | |
grouping = 4 | |
for idx in range(0, len(registers), grouping): | |
ql.log.info('\t'.join(f'{r:5s}: {ql.arch.regs.read(r):016x}' for r in registers[idx:idx + grouping])) | |
def custom_prepare(self, ql: Qiling) -> None: | |
ql.log.info('Context before starting emulation:') | |
ql.os.set_syscall('write', my_syscall_write) | |
ql.log.info('my_syscall_write registered') | |
self._show_context(ql) |
这里实现了一个 my_syscall_write 函数,然后在 QILING_IDA 类的 custom_prepare 方法中调用 ql.os.set_syscall 来注册 write 的 syscall。
修改 custom_script 后右键 ->Qiling Emulator->Reload User Scripts(后续简称 Qiling 菜单)就会重新加载脚本,最后在 Qiling 菜单点击 Restart ,重新开始运行,结果正常,打印出了 “Hello, World!”。
[+] Received interrupt: 0x2
[=] my_syscall_write called
Hello, World!
[=] my_syscall_write(1, 0x555555568260, 14) = 14
[+] 0x00007fffb7e98afc: my_syscall_write(fd = 0x1, buf = 0x555555568260, count = 0xe) = 0xe
[+] Received interrupt: 0x2
[+] 0x00007fffb7e78a2c: exit_group(code = 0x0) = ?
# 通过显式设置 PC 寄存器指定程序执行入口
上节跑通了 Qiling->Continue,现在尝试 Qiling 菜单的 “设置运行地址”。
首先 Qiling->Restart,在 IDA 里对__libc_start_main 函数下断点,Qiling->Continue。此时会看到成功地断在了这里:

Qiling->View Register,查看 PC 寄存器,确认地址是否一致。这里发现 PC 的值是 0x5E0 + 程序基址。

可以 Qiling->Step,单步几次,会看到 IDA 中的不同颜色,这些颜色代表不同的执行操作。蓝色是单步,绿色的直接运行覆盖的路径。

sub_724 函数是真正的打印函数,将光标移到 sub_724 的第一条指令,Qiling->Set PC,此时打印:
[INFO][(unknown file):0] QIling PC set to 0x724
看到设置好了 PC 后,继续 Qiling->Continue,结果报错:
[x] CPU Context:
[x] x0 : 0x555555554724
[x] x1 : 0x1
[x] x2 : 0x80000000de18
...
[x] PC = 0x0000000000000724 (unreachable)
...
File "C:\Program Files\Python39\lib\site-packages\qiling\core.py", line 771, in emu_start
self.uc.emu_start(begin, end, timeout, count)
File "C:\Program Files\Python39\lib\site-packages\unicorn\unicorn.py", line 547, in emu_start
raise UcError(status)
unicorn.unicorn.UcError: Invalid memory fetch (UC_ERR_FETCH_UNMAPPED)
错误提示 PC 为 0x724 的代码是无法访问的,看寄存器:

这里的 PC 是 0x724,回想之前看 Qiling 寄存器是 IDA 地址 + 基址的形式,于是知道原因是 Qiling->Set PC 设置的是 IDA 地址,没有加上模块基址。
修改 qiling 的 IDA 插件,qilingida.py 如下:
def ql_set_pc(self): | |
if self.qlinit: | |
# ea = IDA.get_current_address() | |
ea = self.qlemu.ql_addr_from_ida(IDA.get_current_address()) | |
self.qlemu.ql.arch.regs.arch_pc = ea | |
logging.info(f"QIling PC set to {hex(ea)}") | |
self.qlemu.status = self.qlemu.ql.save() | |
self.ql_update_views(self.qlemu.ql.arch.regs.arch_pc, self.qlemu.ql) | |
else: | |
logging.error('Qiling should be setup firstly.') |
IDA 插件更新后,先 "Qiling->Unload Plugin" 卸载插件,再 IDA->File->Script file 加载插件,然后重新操作一遍,这次设置 PC 就添上基址了:
[INFO][(unknown file):0] QIling PC set to 0x555555554724
最后,移动光标,点击 sub_724 的最后一条指令,然后 Qiling->Execute Till,会看到这次成功执行,橙色代表 Execute Till 执行过的指令:

可以看到下一条指令就是 0x748:

# 小节
从这里可以看到,qiling 的 IDA 插件其实还不完善,即使是官方的 dev 分支(官方推荐使用 dev 分支),模拟执行 demo 还是有很多问题,所以对初学者不算非常友好。因此这里记录下相关问题的解决建议,供大家参考,后文还会有稍麻烦的 bug 需要解决。
# libxx.so 的模拟执行(排错)
OK,demo 已经跑通了,现在来模拟执行 libxx.so。

可以看到算法的核心几个步骤是 init,encrypt,decrypt。那么首先分析 tps_init 函数。
加载 libxx.so、初始化 qiling 后,不能直接将 PC 寄存器指向 tps_init 函数,因为这时运行环境还没有准备好,比如 tpidr_el0 寄存器,这个寄存器类似与 windows 的 fs 段寄存器(TEB),指向当前线程的运行环境。另外,此时还没有做 so 的重定位,很多 so 里的全局引用是需要重定位的,比如调用一个 memset 函数。
首先 IDA 加载 libxx.so,初始化 qiling(Qiling->Setup),对 libxx.so 的入口地址(start 函数)下断点,然后开始模拟执行(Qiling->Continue),报错:
[x] Syscall ERROR: ql_syscall_futex DEBUG: 'NoneType' object has no attribute 'cur_thread'
Traceback (most recent call last):
File "C:\Program Files\Python39\lib\site-packages\qiling\os\posix\posix.py", line 374, in load_syscall
retval = syscall_hook(self.ql, *params)
File "C:\Program Files\Python39\lib\site-packages\qiling\os\posix\syscall\futex.py", line 43, in ql_syscall_futex
regreturn = ql.os.futexm.futex_wake(ql, uaddr,ql.os.thread_management.cur_thread, val)
AttributeError: 'NoneType' object has no attribute 'cur_thread'
查看源码:
elif op & (FUTEX_PRIVATE_FLAG - 1) == FUTEX_WAKE: | |
regreturn = ql.os.futexm.futex_wake(ql, uaddr,ql.os.thread_management.cur_thread, val) |
futex 是 linux 中的锁,这里的 thread_management 是需要 qiling 启动多线程模式才会初始化的,于是在 qilingida.py 创建 Qiling 实例的时候添加多线程参数:
class QlEmuQiling: | |
def __init__(self): | |
self.path = None | |
self.rootfs = None | |
self.ql: Qiling = None | |
self.status = None | |
self.exit_addr = None | |
self.baseaddr = None | |
self.env = {} | |
def start(self, *args, **kwargs): | |
self.ql = Qiling(argv=self.path, rootfs=self.rootfs, verbose=QL_VERBOSE.DEFAULT, multithread=True, env=self.env, log_plain=True, *args, **kwargs) | |
# ... |
这里日志打印从 QL_VERBOSE.DEBUG 改为 QL_VERBOSE.DEFAULT,减少一些调试内容的输出,然后 multithread 显式打开。再卸载、加载一次 qilingida.py,重新运行,以下报错:
[x] [Thread 2000] Syscall ERROR: ql_syscall_writev DEBUG: A string expected
Traceback (most recent call last):
File "C:\Program Files\Python39\lib\site-packages\qiling\os\posix\posix.py", line 374, in load_syscall
retval = syscall_hook(self.ql, *params)
File "C:\Program Files\Python39\lib\site-packages\qiling\os\posix\syscall\uio.py", line 23, in ql_syscall_writev
ql.os.fd[fd].write(buf)
File "D:\Tools\IDA 7.5\python\3\init.py", line 63, in write
ida_kernwin.msg(text)
File "D:\Tools\IDA 7.5\python\3\ida_kernwin.py", line 236, in msg
return _ida_kernwin.msg(*args)
TypeError: A string expected
这个和之前 demo 的问题一样,只是这次的 syscall 是 writev,不是 write。在 custom_script.py 添加 writev 的 syscall hook,定义 my_syscall_writev 函数,Qiling->Reload User Script 重新加载自定义脚本,重启 qiling 环境运行,这次成功运行到 start 函数:

但注意 tpidr_el0 为 0,代表线程运行环境没有准备好。如果这时直接 Qiling->continue,还会出现另一个报错:
[x] [Thread 2000] PC = 0x000000000009aec0 (unreachable)
[x] [Thread 2000] Memory map:
[x] [Thread 2000] Start End Perm Label Image
[x] [Thread 2000] 00555555554000 - 00555555847000 r-x libxx.so E:\gitRepo\qiling\examples\rootfs\arm64_linux\bin\libxx.so
[x] [Thread 2000] 00555555856000 - 0055555588f000 rw- libxx.so E:\gitRepo\qiling\examples\rootfs\arm64_linux\bin\libxx.so
[x] [Thread 2000] 0055555588f000 - 00555555891000 rwx [hook_mem]
[x] [Thread 2000] 007ffffffde000 - 0080000000e000 rwx [stack]
Traceback (most recent call last):
...
File "C:\Program Files\Python39\lib\site-packages\unicorn\unicorn.py", line 547, in emu_start
raise UcError(status)
unicorn.unicorn.UcError: Invalid memory fetch (UC_ERR_FETCH_UNMAPPED)
这里可以看到,PC 准备执行 0x9aec0 处的指令,但从打印的内存映射来看,0x9aec0 是没有映射的,所以导致指令读取失败。
再更仔细地看内存映射信息,发现没有动态链接器加载到内存空间,用 readelf 看一下:
$ readelf -S libxx.so | grep interp
---
$ readelf -S arm64_hello | grep interp
[ 1] .interp PROGBITS 0000000000000200 00000200
libxx.so 没有 interp 节,而 arm64_hello 有,所以 qiling 在加载 libxx.so 的时候没有加载动态链接器。
那现在需要给 libxx.so 显示指定动态链接器,为确定在哪指定,先打开 debug 级别的日志输出:
def start(self, *args, **kwargs):
self.ql = Qiling(argv=self.path, rootfs=self.rootfs, verbose=QL_VERBOSE.DEBUG, multithread=True, env=self.env, log_plain=True, *args, **kwargs)
重新加载 qilingida.py,初始化 qiling 环境,结果没有相关输出。再用 IDA 打开 arm64_hello,相关输出如下:
[INFO][qilingida:1034] Custom env: {}
[+] Profile: default
[+] Mapped 0x555555554000-0x555555555000
[+] Mapped 0x555555564000-0x555555566000
[+] mem_start : 0x555555554000
[+] mem_end : 0x555555566000
[+] Interpreter path: /lib/ld-linux-aarch64.so.1
[+] Interpreter addr: 0x7ffff7dd5000
[+] Mapped 0x7ffff7dd5000-0x7ffff7df2000
[+] Mapped 0x7ffff7e01000-0x7ffff7e04000
[+] mmap_address is : 0x7fffb7dd6000
看到 arm64_hello 的动态链接器是 /lib/ld-linux-aarch64.so.1,根据这个打印日志,去 qiling 源码查找:
def load_with_ld() | |
def load_elf_segments() | |
# ... | |
# determine interpreter path | |
interp_seg = next(elffile.iter_segments(type='PT_INTERP'), None) | |
interp_path = str(interp_seg.get_interp_name()) if interp_seg else '' |
这里的 interp_path 为动态链接器的路径,所以显示指定如下:
if len(interp_path) == 0: | |
interp_path = "/lib/ld-linux-aarch64.so.1" |
重启 qiling 环境,可看到动态链接器的加载:
[INFO][qilingida:1034] Custom env: {}
[+] Profile: default
[+] Mapped 0x555555554000-0x555555847000
[+] Mapped 0x555555856000-0x55555588f000
[+] mem_start : 0x555555554000
[+] mem_end : 0x55555588f000
[+] Interpreter path: /lib/ld-linux-aarch64.so.1
[+] Interpreter addr: 0x7ffff7dd5000
[+] Mapped 0x7ffff7dd5000-0x7ffff7df2000
[+] Mapped 0x7ffff7e01000-0x7ffff7e04000
然后开始 qiling 的模拟执行(Qiling->Continue),如下报错:
[+] [Thread 2000] b'Inconsistency detected by ld.so: '
Inconsistency detected by ld.so: [+] [Thread 2000] b'rtld.c'
rtld.c[+] [Thread 2000] b': '
: [+] [Thread 2000] b'1266'
1266[+] [Thread 2000] b': '
: [+] [Thread 2000] b'dl_main'
dl_main[+] [Thread 2000] b': '
: [+] [Thread 2000] b'Assertion `'
Assertion `[+] [Thread 2000] b'GL(dl_rtld_map).l_libname'
GL(dl_rtld_map).l_libname[+] [Thread 2000] b"' failed!\n"
' failed!
...
File "C:\Program Files\Python39\lib\site-packages\qiling\os\linux\linux.py", line 167, in run
thread_management.run()
File "C:\Program Files\Python39\lib\site-packages\qiling\os\linux\thread.py", line 613, in run
previous_thread = self._prepare_lib_patch()
File "C:\Program Files\Python39\lib\site-packages\qiling\os\linux\thread.py", line 593, in _prepare_lib_patch
raise QlErrorExecutionStop('Dynamic library .init() failed!')
qiling.exception.QlErrorExecutionStop: Dynamic library .init() failed!
第一句话直接提示了该动态链接器不兼容当前 so。想起这个 so 是通过 ndk 编译给安卓用的,那动态链接器应该是安卓下的 linker64。
Bet4 从 qiling 的 github fork 了仓库,里面有 linker64 和安卓下所需的其他 so,比如 libz、libm、liblog。
用 readelf 看到 libxx.so 引用了这些库,所以这里一并准备好,路径如下:
$ readelf -d libxx.so
Dynamic section at offset 0x311f88 contains 29 entries:
Tag Type Name/Value
0x0000000000000001 (NEEDED) Shared library: [liblog.so]
0x0000000000000001 (NEEDED) Shared library: [libz.so]
0x0000000000000001 (NEEDED) Shared library: [libm.so]
0x0000000000000001 (NEEDED) Shared library: [libdl.so]
0x0000000000000001 (NEEDED) Shared library: [libc.so]
0x000000000000000e (SONAME) Library soname: [libtps.so]
0x0000000000000019 (INIT_ARRAY) 0x302dc0
0x000000000000001b (INIT_ARRAYSZ) 8 (bytes)
0x000000000000001a (FINI_ARRAY) 0x302dc8
...
E:\gitRepo\qiling\examples\rootfs\arm64_linux\system\lib64:保存libm.so等库
E:\gitRepo\qiling\examples\rootfs\arm64_linux\lib:保存linker64
该动态链接器更换为 linker64 后,重启 IDA,初始化 qiling 环境,Qiling->Continue,出现以下报错:
[x] [Thread 2000] Disassembly:
[=] [Thread 2000] 00007ffff7ddfbd0 [linker64 + 0x00abd0] 9c 20 40 79 ldrh w28, [x4, #0x10]
[=] [Thread 2000] 00007ffff7ddfbd4 [linker64 + 0x00abd4] 9f 0f 00 71 cmp w28, #3
[=] [Thread 2000] 00007ffff7ddfbd8 [linker64 + 0x00abd8] 81 34 00 54 b.ne #0x7ffff7de0268
...
File "C:\Program Files\Python39\lib\site-packages\qiling\core.py", line 771, in emu_start
self.uc.emu_start(begin, end, timeout, count)
File "C:\Program Files\Python39\lib\site-packages\unicorn\unicorn.py", line 547, in emu_start
raise UcError(status)
unicorn.unicorn.UcError: Invalid memory read (UC_ERR_READ_UNMAPPED)
此时 X4 为 0,导致了内存访问异常。用 IDA 打开 linker64,崩溃点如下:

大致看了上下文,该函数是_dl___linker_init,用来初始化动态库 so,要知道 X4 为什么是 0 还得往上回溯,需要一点时间。且这个 linker64 是安卓低版本 6.0,可能有不兼容的地方,于是我想尝试另外的 linker64,正好手上有一台 PIXEL,于是把里面的 linker64 复制出来,再测试一次,结果如下:
[+] [Thread 2001] b'libc'
libc[+] [Thread 2001] b': '
: [+] [Thread 2001] b'unable to stat "/proc/self/exe": Operation not permitted'
unable to stat "/proc/self/exe": Operation not permitted[+] [Thread 2001] b'\n'
报错无法读取 /proc/self/exe,这是一个符号链接,linker64 用它来获取自身的绝对路径,linker 伪代码如下:

这里用 qiling hook 0x27DA8 地址,然后返回绝对路径和长度,更新 custom_script.py:
def custom_continue(self, ql: Qiling) -> List[HookRet]: | |
# ... | |
def addr_27DA8_hook(ql: Qiling) -> None: | |
ql.arch.regs.W0 = 0 | |
ql.arch.regs.PC += 4 | |
# ... | |
return [ql.hook_address(addr_27DA8_hook, 0x27DA8+linker_baseaddr)] |
重新来一遍,又来一个报错:
[+] [Thread 2000] b'libc'
libc[+] [Thread 2000] b': '
: [+] [Thread 2000] b'Could not find a PHDR: broken executable?'
Could not find a PHDR: broken executable?[+] [Thread 2000] b'\n'
这里找不到 PHDR 程序头表,用 readelf 看一下:
$ readelf -l libxx.so
Elf file type is DYN (Shared object file)
Entry point 0xa5370
There are 8 program headers, starting at offset 64
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
LOAD 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x00000000002f25b4 0x00000000002f25b4 R E 0x10000
LOAD 0x00000000002f2dc0 0x0000000000302dc0 0x0000000000302dc0
0x0000000000034478 0x0000000000037d58 RW 0x10000
DYNAMIC 0x0000000000311f88 0x0000000000321f88 0x0000000000321f88
0x0000000000000210 0x0000000000000210 RW 0x8
NOTE 0x0000000000000200 0x0000000000000200 0x0000000000000200
0x0000000000000024 0x0000000000000024 R 0x4
NOTE 0x00000000002f251c 0x00000000002f251c 0x00000000002f251c
0x0000000000000098 0x0000000000000098 R 0x4
GNU_EH_FRAME 0x00000000002da5dc 0x00000000002da5dc 0x00000000002da5dc
0x000000000000355c 0x000000000000355c R 0x4
GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 RW 0x10
GNU_RELRO 0x00000000002f2dc0 0x0000000000302dc0 0x0000000000302dc0
0x0000000000025240 0x0000000000025240 R 0x1
一般 PHDR 是程序表 (program table) 的第一个元素,这里确实没有。看一下 IDA:

这里也出现了一个变量 + 0x10 的判断,对比 Bet4 的 linker64 上下文和 PIXEL 的 linker64 上下文,可确定是同一个问题,看来必须要往上逆向一下了。
图的注释是分析后的结果。
这里有两种方式,一种是打 trace,即使用 Qiling 的 hook_code,在每一条代码运行前打印现场环境,一种是断在对应的代码,单步做动态调试,这里我选择动态调试的方式。那如何断在对应的代码地址呢,这里要熟悉下 qilingida.py 的这部分代码:
def ql_continue(self): | |
logging.info("before continue...") | |
if self.qlinit: | |
userhook = None | |
# 调用 hook_code,每条指令执行前调用 ql_path_hook | |
pathhook = self.qlemu.ql.hook_code(self.ql_path_hook) | |
def ql_path_hook(self, ql, addr, size): | |
addr = addr - self.qlemu.baseaddr + get_imagebase() | |
set_color(addr, CIC_ITEM, 0x007FFFAA) | |
# 获取断点数量 | |
bp_count = get_bpt_qty() | |
bp_list = [] | |
if bp_count > 0: | |
for num in range(0, bp_count): | |
bp_list.append(get_bpt_ea(num)) | |
# 如果当前准备执行的指令是断点处的指令,调用 ql.save 和 ql.os.stop () 保存当前模拟执行环境 | |
if addr in bp_list and (addr != self.lastaddr or self.is_change_addr>1): | |
self.qlemu.status = ql.save() | |
ql.os.stop() | |
self.lastaddr = addr | |
self.is_change_addr = -1 | |
jumpto(addr) | |
self.is_change_addr += 1 |
这部分代码表示让模拟执行跑起来时,如果遇到断点,就保存现场环境并停下来,所以断在想分析的代码地址处可以在 ql_path_hook 手动加一个断点,如下:
def ql_path_hook(self, ql, addr, size): | |
addr = addr - self.qlemu.baseaddr + get_imagebase() | |
set_color(addr, CIC_ITEM, 0x007FFFAA) | |
bp_count = get_bpt_qty() + 1 | |
bp_list = [] | |
bp_list.append(0x27f2c+0x007ffff7dd5000-0x555555554000) | |
if bp_count > 0: | |
for num in range(0, bp_count): | |
bp_list.append(get_bpt_ea(num)) |
这里给 bp_list 加一个元素,0x27f2c 为相对虚拟地址 (RVA),后面是重定位的基址调整,这样就能断下来,然后单步调试了。
因为第二行 addr 变量重定位时减去的 libxx 模块的基址,所以 bp_list 添加的元素要减去 libxx 模块的基址,而不是 0x27f2c+0x007ffff7dd5000-0x007ffff7dd5000=0x27f2c。
因为中断后,PC 寄存器指向 linker64 模块,所以会报以下错误,不过该错误不影响继续单步调试:
[x] [Thread 2000] [Thread 2000] Expect 0x5555555f9370 but get 0x7ffff7e9e920 when running loader. Traceback (most recent call last): ... File "C:\Program Files\Python39\lib\site-packages\qiling\os\linux\linux.py", line 167, in run thread_management.run() File "C:\Program Files\Python39\lib\site-packages\qiling\os\linux\thread.py", line 613, in run previous_thread = self._prepare_lib_patch() File "C:\Program Files\Python39\lib\site-packages\qiling\os\linux\thread.py", line 593, in _prepare_lib_patch raise QlErrorExecutionStop('Dynamic library .init() failed!') qiling.exception.QlErrorExecutionStop: Dynamic library .init() failed!
单步调试后,伪代码如下:
i = 0; | |
while (program_table_element[i].p_type!=PT_PHDR) { | |
i++; | |
if (i >= elf_header.e_phnum) | |
break; | |
} | |
if (i == elf_header.e_phnum) { | |
print("no phdr"); | |
} | |
else { | |
// 获取文件基址在内存的地址 | |
a = phdr_addr - program_table_element[i].p_paddr; | |
// 获取内存基址 | |
b = phdr_addr - program_table_elemet[i].p_offset; | |
} |
这里可以模拟程序头表获取变量 a 和变量 b,修改 custom_script.py 如下:
def custom_continue(self, ql: Qiling) -> List[HookRet]: | |
#... | |
def addr_27FB4_hook(ql: Qiling) -> None: | |
# 如果是检测第一个程序表元素,且不是程序头表 | |
if ql.arch.regs.X11 == 0 and ql.arch.regs.W12 == 1: | |
phdr_vir_addr = ql.arch.regs.X8 | |
poffset_addr = ql.arch.regs.x10 | |
write_base = ql.arch.regs.X19 | |
ql.log.info(f'phdr_vir_addr: {phdr_vir_addr:#x}') | |
ql.log.info(f'poffset_addr: {poffset_addr:#x}') | |
sub1 = to_bstring(phdr_vir_addr-0x40) | |
# *(QWORD*)((__int64)v50+0x100) = image_vir_addr | |
ql.mem.write(write_base+0x100, sub1) | |
ql.log.info(b'sub1: ' + sub1) | |
image_vir_addr = phdr_vir_addr-0x40 | |
# *(QWORD*)((__int64)v50+0x10) = image_vir_addr | |
ql.mem.write(write_base+0x10, to_bstring(0x40)) | |
ql.log.info(f'sub2: {image_vir_addr:#x}') | |
ql.arch.regs.X8 = image_vir_addr | |
ql.arch.regs.PC = 0x28070 + 0x7ffff7dd5000 | |
ql.hook_address(addr_27FB4_hook, 0x27FB4+linker_baseaddr) |
记得把之前在 qilingida.py 添加的断点去掉。
重启 qiling 环境,这样就能够断在 libxx.so 的 start 地址处了。
遗憾的是,到这里仍然不能顺利模拟执行我们的目标函数,因为 qiling 模拟执行到 start 大约需要 3-4 分钟,如果每次分析调整完 qiling 代码后,都重启一次 qiling,那这个效率就太低了。
写这篇文章的时候,为了演示,我重新又走了一遍流程,结果这次直接卡死了,IDA 一直消耗 CPU 一整晚,到白天都还没有弄完:
经过分析,发现通过 Qiling->Continue 的方式,每执行一条执行都会调用设置的 callback(qilingida.py->ql_path_hook),如果取消这个回调注册,qiling 就会大约 2-3 秒来到 start 地址处。
重启 qiling 环境,这次遇到了这个错误:
[x] [Thread 2000] v28 : 0x0
[x] [Thread 2000] v29 : 0x0
[x] [Thread 2000] v30 : 0x0
[x] [Thread 2000] v31 : 0x0
[x] [Thread 2000] PC = 0x0000000000000000 (unreachable)
[x] [Thread 2000] Memory map:
[x] [Thread 2000] Start End Perm Label Image
[x] [Thread 2000] 00555555554000 - 00555555847000 r-x libxx.so E:\gitRepo\qiling\examples\rootfs\arm64_linux\bin\libxx.so
[x] [Thread 2000] 00555555856000 - 0055555587c000 r-- libxx.so E:\gitRepo\qiling\examples\rootfs\arm64_linux\bin\libxx.so
[x] [Thread 2000] 0055555587c000 - 0055555588f000 rw- libxx.so E:\gitRepo\qiling\examples\rootfs\arm64_linux\bin\libxx.so
[x] [Thread 2000] 0055555588f000 - 00555555891000 rwx [hook_mem]
[x] [Thread 2000] 007fffb7dd6000 - 007fffb7dd7000 --- [mmap anonymous]
[x] [Thread 2000] 007fffb7dd7000 - 007fffb7dda000 rw- [mmap anonymous]
[x] [Thread 2000] 007fffb7dda000 - 007fffb7ddb000 --- [mmap anonymous]
[x] [Thread 2000] 007fffb7ddb000 - 007fffb7ddc000 --- [mmap anonymous]
[x] [Thread 2000] 007fffb7ddc000 - 007fffb7de0000 rw- [mmap anonymous]
[x] [Thread 2000] 007fffb7de0000 - 007fffb7de1000 r-- [mmap anonymous]
[x] [Thread 2000] 007fffb7de1000 - 007fffb7de2000 rw- [mmap anonymous]
[x] [Thread 2000] 007fffb7de2000 - 007fffb7de3000 rw- [mmap anonymous]
[x] [Thread 2000] 007fffb7de3000 - 007fffb7de4000 rw- [mmap anonymous]
[x] [Thread 2000] 007fffb7de5000 - 007fffb7de6000 rw- [mmap anonymous]
[x] [Thread 2000] 007fffb7de6000 - 007fffb7de7000 r-- [mmap anonymous]
[x] [Thread 2000] 007fffb7de7000 - 007fffb7de8000 --- [mmap anonymous]
[x] [Thread 2000] 007fffb7de8000 - 007fffb7de9000 rw- [mmap anonymous]
[x] [Thread 2000] 007fffb7de9000 - 007fffb7dea000 --- [mmap anonymous]
[x] [Thread 2000] 007fffb7dea000 - 007fffb7deb000 r-- [mmap anonymous]
[x] [Thread 2000] 007fffb7deb000 - 007fffb7dec000 rw- [mmap anonymous]
[x] [Thread 2000] 007fffb7dec000 - 007fffb7ded000 rw- [mmap anonymous]
[x] [Thread 2000] 007fffb7ded000 - 007fffb7dee000 rw- [mmap anonymous]
[x] [Thread 2000] 007fffb7dee000 - 007fffb7def000 rw- [mmap anonymous]
[x] [Thread 2000] 007fffb7def000 - 007fffb7df0000 rw- [mmap anonymous]
[x] [Thread 2000] 007fffb7df0000 - 007fffb7df1000 r-- [mmap anonymous]
[x] [Thread 2000] 007fffb7df1000 - 007fffb7df2000 rw- [mmap anonymous]
[x] [Thread 2000] 007fffb7e31000 - 007fffb7e32000 rw- [mmap anonymous]
[x] [Thread 2000] 007fffb7e32000 - 007fffb7e33000 rw- [mmap anonymous]
[x] [Thread 2000] 007fffb7e4b000 - 007fffb7f0e000 r-x [mmap] libc.so
[x] [Thread 2000] 007fffb7f0e000 - 007fffb7f1d000 --- [mmap anonymous]
[x] [Thread 2000] 007fffb7f1d000 - 007fffb7f23000 r-- [mmap] libc.so
[x] [Thread 2000] 007fffb7f23000 - 007fffb7f26000 rw- [mmap] libc.so
[x] [Thread 2000] 007fffb7f26000 - 007fffb7f34000 rw- [mmap anonymous]
[x] [Thread 2000] 007fffb7f5d000 - 007fffb7f5e000 r-x [mmap] libdl.so
[x] [Thread 2000] 007fffb7f5e000 - 007fffb7f6d000 --- [mmap anonymous]
[x] [Thread 2000] 007fffb7f6d000 - 007fffb7f6e000 r-- [mmap] libdl.so
[x] [Thread 2000] 007fffb7f6e000 - 007fffb7f6f000 rw- [mmap] libdl.so
[x] [Thread 2000] 007fffb7f81000 - 007fffb8058000 r-x [mmap] libc++.so
[x] [Thread 2000] 007fffb8058000 - 007fffb8067000 --- [mmap anonymous]
[x] [Thread 2000] 007fffb8067000 - 007fffb806e000 r-- [mmap] libc++.so
[x] [Thread 2000] 007fffb806e000 - 007fffb806f000 rw- [mmap] libc++.so
[x] [Thread 2000] 007fffb806f000 - 007fffb8072000 rw- [mmap anonymous]
[x] [Thread 2000] 007fffb80b5000 - 007fffb80ed000 r-x [mmap] libm.so
[x] [Thread 2000] 007fffb80ed000 - 007fffb80fd000 --- [mmap anonymous]
[x] [Thread 2000] 007fffb80fd000 - 007fffb80fe000 r-- [mmap] libm.so
[x] [Thread 2000] 007fffb80fe000 - 007fffb80ff000 rw- [mmap] libm.so
[x] [Thread 2000] 007fffb8106000 - 007fffb8122000 r-x [mmap] libz.so
[x] [Thread 2000] 007fffb8122000 - 007fffb8131000 --- [mmap anonymous]
[x] [Thread 2000] 007fffb8131000 - 007fffb8132000 r-- [mmap] libz.so
[x] [Thread 2000] 007fffb8132000 - 007fffb8133000 rw- [mmap] libz.so
[x] [Thread 2000] 007fffb8160000 - 007fffb8165000 r-x [mmap] liblog.so
[x] [Thread 2000] 007fffb8165000 - 007fffb8174000 --- [mmap anonymous]
[x] [Thread 2000] 007fffb8174000 - 007fffb8175000 r-- [mmap] liblog.so
[x] [Thread 2000] 007fffb8175000 - 007fffb8176000 rw- [mmap] liblog.so
...
File "C:\Program Files\Python39\lib\site-packages\qiling\core.py", line 771, in emu_start
self.uc.emu_start(begin, end, timeout, count)
File "C:\Program Files\Python39\lib\site-packages\unicorn\unicorn.py", line 547, in emu_start
raise UcError(status)
unicorn.unicorn.UcError: Invalid memory fetch (UC_ERR_FETCH_UNMAPPED)
这里 PC 跳到了 0x0,不过我们可以看到 libxx.so 需要的依赖库都被完美地加载到内存了,说明动态链接器加载 libxx.so 应该是完成了。
因为取消了 ql_path_hook 的回调,所以不能断到断点处,所以得另外用一种方法断到 start 地址处。
qiling 有一个 “运行到” 的函数,右键是 Qiling->Execute Till,观察 qiling 的 IDA 插件:
def ql_run_to_here(self): | |
if self.qlinit: | |
curr_addr = get_screen_ea() | |
# 每执行一条命令前,调用 ql_until_hook | |
untillhook = self.qlemu.ql.hook_code(self.ql_untill_hook) | |
if self.qlemu.status is not None: | |
self.qlemu.ql.restore(self.qlemu.status) | |
show_wait_box("Qiling is processing ...") | |
try: | |
self.qlemu.run(begin=self.qlemu.ql.arch.regs.arch_pc, end=curr_addr+self.qlemu.baseaddr-get_imagebase()) | |
finally: | |
hide_wait_box() | |
else: | |
show_wait_box("Qiling is processing ...") | |
try: | |
self.qlemu.run(end=curr_addr+self.qlemu.baseaddr-get_imagebase()) | |
finally: | |
hide_wait_box() |
qiling 在 run 方法中提供了 end,代表模拟执行在哪里结束。我们可以把 end 设置为 start 地址就相当于断在 start 上了,通过在 IDA 将光标移到对应的代码处即可设置 end。不过这里也有一个指令级回调(第 5 行),观察 ql_until_hook 的实现:
def ql_untill_hook(self, ql, addr, size): | |
addr = addr - self.qlemu.baseaddr + get_imagebase() | |
set_color(addr, CIC_ITEM, 0x00B3CBFF) |
该函数只是将模拟执行过的代码设置高亮,因此我们可以直接注视掉这个回调的注册(在 ql_run_to_here 去掉对 ql_until_hook 的 hook_code 和 hook_del 调用)。另外,之前在 custom_continue 设置的回调都要 copy 一份到 custom_run_to_here,由于 custom_script.py 没有 custom_run_to_here 函数,那么就创建一个:
qilingida.py:
def ql_run_to_here(self): | |
if self.qlinit: | |
curr_addr = get_screen_ea() | |
userhook = None | |
# 注册新创建的 custom_run_to_here 方法 | |
if self.userobj is not None: | |
userhook = self.userobj.custom_run_to_here(self.qlemu.ql) | |
# 去掉 ql_until_hook 的回调 | |
# untillhook = self.qlemu.ql.hook_code(self.ql_untill_hook) | |
if self.qlemu.status is not None: | |
self.qlemu.ql.restore(self.qlemu.status) | |
show_wait_box("Qiling is processing ...") | |
try: | |
self.qlemu.run(begin=self.qlemu.ql.arch.regs.arch_pc, end=curr_addr+self.qlemu.baseaddr-get_imagebase()) | |
finally: | |
hide_wait_box() | |
else: | |
show_wait_box("Qiling is processing ...") | |
try: | |
self.qlemu.run(end=curr_addr+self.qlemu.baseaddr-get_imagebase()) | |
finally: | |
hide_wait_box() | |
set_color(curr_addr, CIC_ITEM, 0x00B3CBFF) | |
# 回调删除部分也注视掉 | |
# self.qlemu.ql.hook_del(untillhook) | |
if userhook and userhook is not None: | |
for hook in userhook: | |
self.qlemu.ql.hook_del(hook) | |
self.qlemu.status = self.qlemu.ql.save() | |
self.ql_update_views(self.qlemu.ql.arch.regs.arch_pc, self.qlemu.ql) | |
else: | |
logging.error('Qiling should be setup firstly.') |
custom_script.py:
def custom_run_to_here(self, ql: Qiling) -> List[HookRet]: | |
linker_baseaddr = 0x007ffff7dd5000 | |
def addr_27DA8_hook(ql: Qiling) -> None: | |
# content from custom_continue | |
def addr_27FB4_hook(ql: Qiling) -> None: | |
# content from custom_continue | |
return [ql.hook_address(addr_27DA8_hook, 0x27DA8+linker_baseaddr), | |
ql.hook_address(addr_27FB4_hook, 0x27FB4+linker_baseaddr)] |
OK,输出终于没有报错了,观察寄存器,也顺利执行到了 start 地址处:

修改之后,重启 qiling 环境,将光标移到 start 代码处,右键 Qiling->Execute Till。
接下来就是单步执行了,结果遇到如下问题:
[=] [Thread 2000] custom_step hook
[=] [Thread 2001] Executing: 0x7ffff7e0373c
[x] [Thread 2001] [Thread 2001] Expect 0x5555555f9370 but get 0x7ffff7e03740 when running loader.
File "C:\Program Files\Python39\lib\site-packages\qiling\os\linux\thread.py", line 611, in run
previous_thread = self._prepare_lib_patch()
File "C:\Program Files\Python39\lib\site-packages\qiling\os\linux\thread.py", line 590, in _prepare_lib_patch
raise QlErrorExecutionStop('Dynamic library .init() failed!')
qiling.exception.QlErrorExecutionStop: Dynamic library .init() failed!
这里显示单步执行的命令地址是 0x7ffff7e0373c,而不是 0x5555555f9370。要定位这个问题需要了解 qiling 源码,分析流程如下:
# qilingida.py | |
# 单步执行的入口是 qlemu.run | |
def ql_step(self): | |
self.qlemu.run(begin=self.qlemu.ql.arch.regs.arch_pc, end=self.qlemu.exit_addr) | |
# qiling/os/linux/linux.py | |
class QlOsLinux(QlOsPosix): | |
def run(self): | |
if self.ql.multithread: | |
# start multithreading | |
# 多线程环境下调用 thread_management.run () | |
thread_management = thread.QlLinuxThreadManagement(self.ql) | |
self.ql.os.thread_management = thread_management | |
thread_management.run() | |
else: | |
# 单线程环境 | |
if self.ql.entry_point is not None: | |
self.ql.loader.elf_entry = self.ql.entry_point | |
# do we have an interp? | |
# 如果有动态链接器,就用动态链接器初始化目标 so | |
elif self.ql.loader.elf_entry != self.ql.loader.entry_point: | |
entry_address = self.ql.loader.elf_entry | |
if self.ql.arch.type == QL_ARCH.ARM: | |
entry_address &= ~1 | |
# start running interp, but stop when elf entry point is reached | |
self.ql.emu_start(self.ql.loader.entry_point, entry_address, self.ql.timeout) | |
# 开始模拟执行目标 so | |
self.ql.emu_start(self.ql.loader.elf_entry, self.exit_point, self.ql.timeout, self.ql.count) | |
# qiling/os/linux/thread.py | |
class QlLinuxThreadManagement: | |
def run(self): | |
# 调用_prepare_lib_patch,让动态链接器加载目标 libxx.so | |
previous_thread = self._prepare_lib_patch() | |
def _prepare_lib_patch(self): | |
# 如果有动态链接器,就用动态链接器初始化目标 libxx.so | |
if self.ql.loader.elf_entry != self.ql.loader.entry_point: | |
entry_address = self.ql.loader.elf_entry | |
if self.ql.arch.type == QL_ARCH.ARM: | |
entry_address &= ~1 | |
self.main_thread = self.ql.os.thread_class.spawn(self.ql, self.ql.loader.entry_point, entry_address) | |
self.cur_thread = self.main_thread | |
self._clear_queued_msg() | |
gevent.joinall([self.main_thread], raise_error=True) | |
if self.ql.arch.regs.arch_pc != entry_address: | |
self.ql.log.error(f"{self.cur_thread} Expect {hex(self.ql.loader.elf_entry)} but get {hex(self.ql.arch.regs.arch_pc)} when running loader.") | |
raise QlErrorExecutionStop('Dynamic library .init() failed!') | |
self.ql.do_lib_patch() | |
self.ql.os.run_function_after_load() | |
self.ql.loader.skip_exit_check = False | |
self.ql.write_exit_trap() | |
return self.main_thread | |
return None |
观察代码流程,我们发现单线程环境下,如果指定了 ql.entry_point(调用 ql.run 的 begin 参数),就不会用动态加载器去重定位,而是直接开始模拟执行。这是正常的,因为第一次模拟执行时我们一般不会指定 ql.run 的 begin 参数,而是让动态链接器去初始化 so,不过我们会注册一些回调,使得之后可以保存快照和恢复模拟执行,而恢复模拟执行就会设置 ql.run 的 begin 参数。再看多线程的环境,qiling 官方显然没有考虑到这个,每次调用 ql.run 都会执行_prepare_lib_path,都用动态链接器初始化 so。在我们的场景下,我们已经初始化过 libxx.so,想要开始单步调试 so,而由于 qiling 又一次初始化 libxx.so,所以单步调试后的下一条指令是动态加载器的入口地址 + 4,而不是 libxx.so 的入口地址 + 4。
这里直接模仿单线程环境,修改如下:
# qiling/os/linux/thread.py | |
def _prepare_lib_patch(self): | |
if self.ql.entry_point is not None: | |
self.ql.loader.elf_entry = self.ql.entry_point | |
return None | |
elif self.ql.loader.elf_entry != self.ql.loader.entry_point: | |
entry_address = self.ql.loader.elf_entry |
这里添加一个 ql.entry_point 的判断,如果 ql.run 设置了 begin,就不重定位,直接从 begin 地址处开始模拟执行。
重启 qiling 环境,再次执行 Qiling->Execute Till:
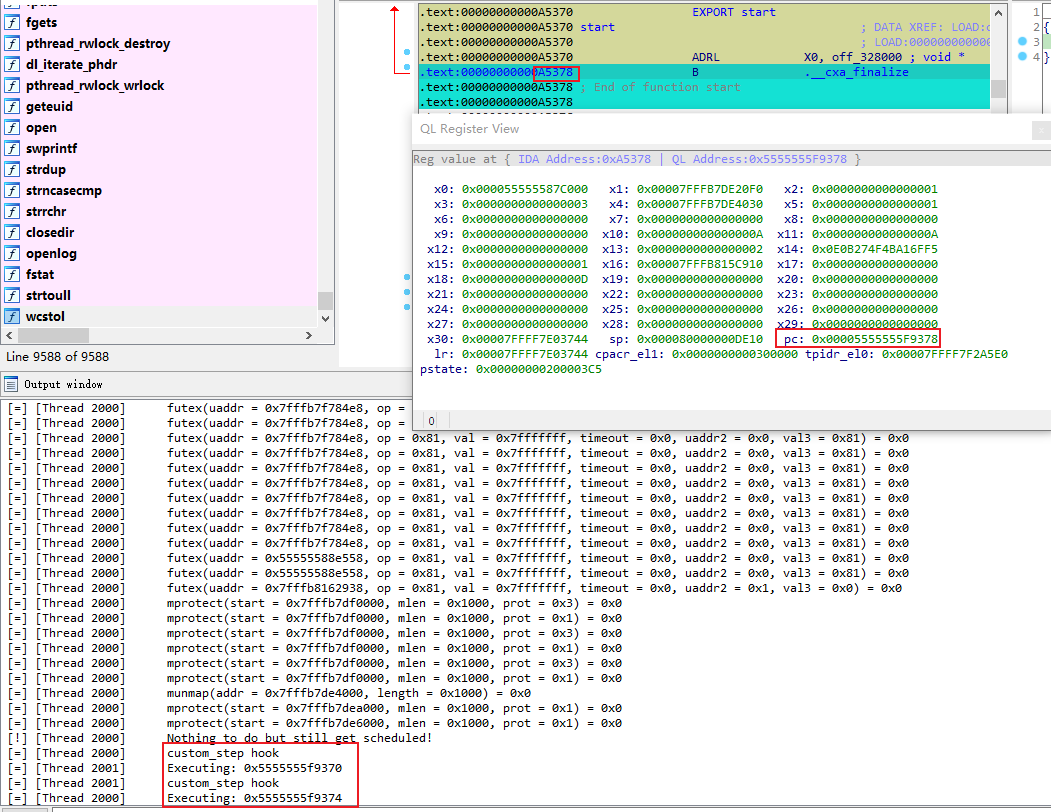
可以看到,这次单步调试成功了,顺利断在了 libxx.so 的下一条指令。
继续单步执行,进入 ".__cxa_finalize" 函数,该函数是从内存读取__cxa_finalize 真正的函数地址并执行,该函数地址是需要重定位的,因为该函数属于其他模块,我们观察其内存:

__cxa_finalize_ptr 是保存函数地址的指针,通过 IDA View-B 可看到其相对虚拟地址是 0x3266D0,X16 寄存器保存了__cxa_finalize_ptr 所在的内存页,我们查看内存,发现 0x6D0 偏移处是 0x7FFFB80F942C,该地址位于 libc.so 中,所以由此得知动态链接器正确地完成了 libxx.so 的重定位。
[x] [Thread 2000] 007fffb8085000 - 007fffb8148000 r-x [mmap] libc.so
# 虚拟机框架解析
libxx.so 有 3 个重要的接口:
- tps_init:tps_init 初始化和收集环境信息,发送给服务器
- tps_encrypt、tps_decrypt:负责数据的加解密
因为 tps_init 与算法无关,这里就直接忽略了。
先看下加解密函数的伪代码:
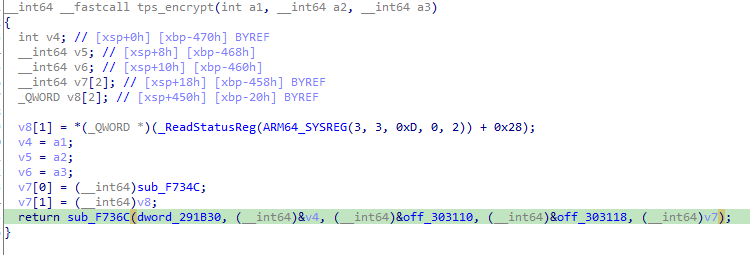
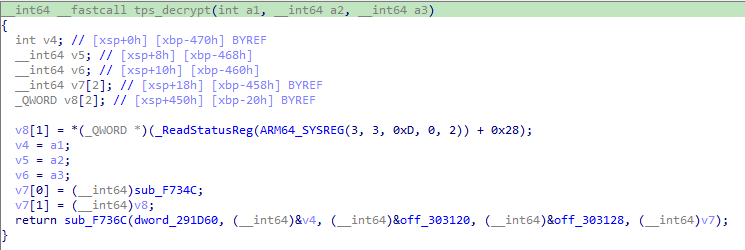
两个函数结构一致,sub_F736C 是真正的加解密函数,加密与解密的不同在于 sub_F736C 的第 1、3、4 参数。
# 虚拟机的简要流程
回顾 sub_F736C 的整体结构:

感觉像是几层嵌套的控制流平坦化,通过单步模拟执行,其实际上是一个虚拟机的简化版,这里简要说明其流程:
初始化一些计算因子,然后进入 while (1) 无限循环,v66 从 a1 参数读取一个四字节大小的无符号整形,然后与 0x3F 做 & 算法,最后传给 switch
这里 IDA 反编译出现了一点问题,传给 switch 的不是 v39
![image-20240725134708083]()
一个大 switch
![image-20240725110152019]()
假如 v39 是 0x9,跳到对应的 case,执行 [vmstack-off1] = [vmstack-off2] + number,之后跳到 LABEL_331
![image-20240725110448988]()
LABEL_331 是所有 case 的最后一段代码,类似 switch 的所有 case 都没有 break,然后都跳转到了 default 分支下
![image-20240725135938807]()
LABEL_331 有两个功能:
改变控制流,做指令跳转
一种是 a1 数组自增到下一个元素
a1 = (unsigned int *)(*(_QWORD *)beg + 4LL);
*(_QWORD *)beg = a1;
一种是直接跳转到 a1 数组的某个元素
//func_data - 0x18 地址处保存的是上一个 switch-case 写入的值a1 = *(unsigned int **)(func_data - 0x18);
*(_QWORD *)(func_data - 0x20) = 0LL;
*(_QWORD *)beg = a1;
调用回调函数
real_data = ((__int64 (__fastcall *)(_QWORD, _QWORD))func)(*v13, *v14);
最后,回到 while (1),继续走 switch。




# 虚拟机结构剖析
switch-case 的参数来源:sub_F736C 的第一个参数是一个 4 字节数组,每个 4 字节的一部分都是 switch-case 的参数,用来执行一个操作。
![image-20240725113411862]()
因此每一个 4 字节就是一个 handler,其 handler 的内部解析如下,handler index 和 subhandler index 为 switch-case 的参数。
![image-20240725135546287]()
handler 的执行示例:
handler index:0x2B subhandler index:0xC2B handler:[vm_stack-off3] = [vm_stack-off1] + [vm_stack-off2] example: [=] [Thread 2008] index: 0xc2b -> [func_data-0x110] = [func_data-0x80] + [func_data-0x128]; 0xffffffffff971488, 0x555555cd9eb0, rs: 0x55555564b338 ------------------------------------------------ handler index:0x2B subhandler index:0xA6B handler:[vm_stack-off3] = [vm_stack-off1] >> operand2 example: [=] [Thread 2008] index: 0xa6b -> [func_data-0x128] = d[func_data-0x88] >> 0x18; 0x555f9370, rs: 0x55 ------------------------------------------------ handler index:0x9 no subhandler index handler:[vm_stack-off1] = [vm_stack-off2] + operand1 example: [=] [Thread 2008] index: 0x9 -> [func_data-0x120] = [func_data-0x130] + 0x4; 0x0, rs: 0x4看第一个例子,index 为 0x2B,则进一步判断 subindex,执行 subindex 为 0xC2B 的操作,这里有 3 个变量,off1、off2、off3,分别从 handler 中做位运算提取。
控制流的变化
加解密的执行就是遍历 handler 数组实现的,一个 handler 一个 handler 的执行。对于 for 循环,虚拟机需要改变控制流来实现,以下给出控制流改变的一个例子:
[=] [Thread 2008] index: 0x34 -> [func_data-0x130]; 0x0 [func_data-0x128]; 0x1 [func_data-0x18] = index_table_pointer+4+((int)(0xfffc << 0x10) >> 0xE); 0x5555557e5bd0 [func_data-0x20] = 2 [=] [Thread 2008] index: 0x9 -> [func_data-0x120] = [func_data-0x120] + 0x1; func_data-0x234, rs: func_data-0x233 index_table_pointer = [func_data-0x18]; 0x5555557e5bc4 [func_data-0x20] = 0 [beg] = index_table_pointer执行 0x34 handler,如果 *(DWORD*)(func_data-0x130)!= *(DWORD*)(func_data-0x128),handler 数组指针就减 0xC,并且 func_data-0x20 地址处写入 2,表示下一个 handler 执行后即将跳转:
index_table_pointer+4+((int)(0xfffc << 0x10) >> 0xE) = index_table_pointer-0xC = 0x5555557e5bd0-0xC= 0x5555557e5bc4执行下一条 0x9 handler 时,因为 func_data-0x20 地址处的值为 2,所以让 handler 跳转到 0x5555557e5bc4。
如果 0x34 handler 执行时 *(DWORD*)(func_data-0x130)== *(DWORD*)(func_data-0x128),那么下一个 handler 执行后仍顺序执行。


# 虚拟机执行流程解析
每次执行一个 handler,相当于进入 switch 走一遍,因为我们已经解析了 handler4 字节的内部组成,所以我们可以记录每一条 handler 具体代表的语义。每当进入 switch 时,我们把当前 handler 的语义打出来,就可以看到完整的加解密流程了。

于是,我们调用 ql.hook_code 方法,每当执行到 0xF7E20 这,就打印 handler 语义:
更新 custom_script.py:
def custom_run_to_here(self, ql: Qiling) -> List[HookRet]: | |
def addr_tps_F7E20_hook(ql: Qiling) -> None: | |
# ql.log.info(f'index_base: {ql.arch.regs.X19:#x}') | |
index = ql.arch.regs.X12 & 0x3F | |
# ql.log.info(f'index_value: {index:#x}') | |
# ql.log.info(f'off1: {ql.arch.regs.W8:#x}') | |
# ql.log.info(f'off2: {ql.arch.regs.W9:#x}') | |
indent = f'\n\t\t\t\t\t\t' | |
off = calc_off(ql) | |
W11 = calc_W11(ql) | |
rs = f'index: {index:#x} -> ' | |
base_W8 = f'[func_data-{0x130-ql.arch.regs.W8*8:#x}]' | |
base_W9 = f'[func_data-{0x130-ql.arch.regs.W9*8:#x}]' | |
base_W10 = f'[func_data-{0x130-ql.arch.regs.W10*8:#x}]' | |
global update_index_table_flag | |
if update_index_table_flag == 2: | |
update_index_table_flag += 1 | |
if index == 0x9 or index == 0x1C: | |
base_W9_value = get_base_W9(ql) | |
rs += f'{base_W8} = {base_W9} + {off:#x}; {get_base(ql, base_W9_value)}, rs: {get_base(ql, base_W9_value+off)}' | |
elif index in [0, 0x34]: | |
flag_20 = ql.arch.regs.X0 | |
if flag_20 != 0: | |
rs += "ignore!!" | |
v78 = f'(int)({off:#x} << 0x10) >> 0xE' | |
v77 = get_base_W8(ql) | |
rs += f'{base_W8}; {v77:#x}' | |
v79 = get_base_W9(ql) | |
rs += f'{indent}{base_W9}; {v79:#x}' | |
str1 = f'{indent}[func_data-0x18] = index_table_pointer+8(2 elements); {ql.arch.regs.X19:#x}, rs: {ql.arch.regs.X19+8:#x}' | |
str2 = f'{indent}[func_data-0x18] = index_table_pointer+4+({v78}); {ql.arch.regs.X19:#x}' | |
if index == 0: | |
if v77 != v79: | |
rs += str1 | |
else: | |
rs += str2 | |
if index == 0x34: | |
if v77 == v79: | |
rs += str1 | |
else: | |
rs += str2 | |
# elif... | |
if log_flag: | |
ql.log.info(rs) | |
return [ql.hook_address(addr_27DA8_hook, 0x7ffff7dfcda8), | |
ql.hook_address(addr_27FB4_hook, 0x7ffff7dfcfb4), | |
ql.hook_address(addr_tps_ADAB8_hook, 0x555555601ab8), | |
ql.hook_address(addr_tps_F7E20_hook, 0x55555564be20)] |
完整的 custom_script.py 已上传至附件。
因为 switch-case 有些路径是没有走到的,也就是说加解密的 handler 不是全集,所以我们在写 handler 的时候,只需要一个一个写,遇到一个新的待执行的 handler,就增加一个 elif,不需要把 switch-case 的所有路径都挨着写完。
当我们新增 handler 时,就需要重启 qiling 环境,这样会很耗时。因此在遇到没有记录的 handler 时,我们可以手动调用 ql.os.stop (),这样 ql_run_to_here 可以为我们保存当前执行环境,之后我们仍然可以单步模拟执行:
# qilingida.py# ...# 当 qlemu.run 方法在模拟执行时,如果 custom_run_to_here 调用了 ql.os.stop (),# 那么 qlemu.run 就会返回。# qlemu.run 返回后保存当前模拟执行环境。# custom_script.pyglobal log_flag
模拟执行的输出结果示例如下:
[=] [Thread 2008] index: 0x9 -> [func_data-0x48] = [func_data-0x48] + 0xfea0; func_data-0x150, rs: func_data--0xfd50
[=] [Thread 2008] index: 0x29 -> [[func_data-0x48]+0x158] = [func_data-0x38]; func_data-0x158, 0x0
[=] [Thread 2008] index: 0x29 -> [[func_data-0x48]+0x150] = [func_data-0x80]; func_data-0x160, 0x0
[=] [Thread 2008] index: 0x29 -> [[func_data-0x48]+0x148] = [func_data-0x88]; func_data-0x168, 0x0
[=] [Thread 2008] index: 0x29 -> [[func_data-0x48]+0x140] = [func_data-0x90]; func_data-0x170, 0x0
[=] [Thread 2008] index: 0x29 -> [[func_data-0x48]+0x138] = [func_data-0x98]; func_data-0x178, 0x0
[=] [Thread 2008] index: 0x29 -> [[func_data-0x48]+0x130] = [func_data-0xa0]; func_data-0x180, 0x0
[=] [Thread 2008] index: 0x29 -> [[func_data-0x48]+0x128] = [func_data-0xa8]; func_data-0x188, 0x0
[=] [Thread 2008] index: 0x29 -> [[func_data-0x48]+0x120] = [func_data-0xb0]; func_data-0x190, 0x0
[=] [Thread 2008] index: 0x3c -> [func_data-0xb0] = [[func_data-0x110] + 0x10]; func_data-0x450 -> func_data-0x440, 0x20
[=] [Thread 2008] index: 0x3c -> [func_data-0xa8] = [[func_data-0x110] + 0x8]; func_data-0x450 -> func_data-0x448, 0x100000
[=] [Thread 2008] index: 0x3c -> [func_data-0x90] = [[func_data-0x108] + 0x0]; 0x555555857110 -> 0x555555857110, 0x555555f0abb0
[=] [Thread 2008] index: 0x35 -> [func_data-0x88] = (signed )d[[func_data-0x110] + 0x0]; func_data-0x450, 0x555f9370
[=] [Thread 2008] index: 0x3c -> [func_data-0x128] = [[func_data-0x100] + 0x0]; 0x555555857118 -> 0x555555857118, 0x555555cd9eb0
[=] [Thread 2008] index: 0x2d -> [func_data-0x98] = d[func_data-0x130] + (int64)(int)0x0; 0x0, rs: 0x0
[=] [Thread 2008] index: 0x2a -> b[[func_data-0x48] + 0x110] = b[func_data-0x130]; func_data-0x1a0, 0x0
[=] [Thread 2008] index: 0x9 -> [func_data-0xa0] = [func_data-0x48] + 0x4; func_data-0x2b0, rs: func_data-0x2ac
[=] [Thread 2008] index: 0x29 -> [[func_data-0x48]+0x108] = [func_data-0xa0]; func_data-0x1a8, func_data-0x2ac
[=] [Thread 2008] index: 0x9 -> [func_data-0x120] = [func_data-0x130] + 0x4; 0x0, rs: 0x4
[=] [Thread 2008] index: 0x29 -> [[func_data-0x48]+0x118] = [func_data-0x120]; func_data-0x198, 0x4
[=] [Thread 2008] index: 0x1f -> [func_data-0x120] = int(0xff97 << 0x10)
[=] [Thread 2008] index: 0x1d -> [func_data-0x80] = [func_data-0x120] | 0x1488; 0xffffffffff970000, rs:0xffffffffff971488
[=] [Thread 2008] index: 0xc2b -> [func_data-0x110] = [func_data-0x80] + [func_data-0x128]; 0xffffffffff971488, 0x555555cd9eb0, rs: 0x55555564b338
[=] [Thread 2008] index: 0x92b -> [func_data-0x68] = [func_data-0x130] | [func_data-0xf8]; 0x0, 0x55555564b34c, rs: 0x55555564b34c
[=] [Thread 2008] index: 0xdeb -> [func_data-0x18] = [func_data-0x68]; 0x55555564b34c
[func_data-0x20] = 2
[func_data-0x38] = index_table_pointer+8; 0x5555557e5b90, rs: 0x5555557e5b98
[func_data-0x10] = index_table_pointer+8; 0x5555557e5b90, rs: 0x5555557e5b98
[=] [Thread 2008] index: 0x9 -> [func_data-0x108] = [func_data-0x48] + 0x108; func_data-0x2b0, rs: func_data-0x1a8
index_table_pointer = [func_data-0x18]; 0x55555564b34c
[func_data-0x20] = 0
[beg] = index_table_pointer
call func:(0x55555564b34c)([func_data-0x110], [func_data-0x108]); memset
index_table_pointer = [func_data-0x10]; 0x5555557e5b98
[beg] = index_table_pointer
[=] [Thread 2008] index: 0xa6b -> [func_data-0x128] = d[func_data-0x88] >> 0x18; 0x555f9370, rs: 0x55
[=] [Thread 2008] index: 0xa6b -> [func_data-0x120] = d[func_data-0x88] >> 0x10; 0x555f9370, rs: 0x555f
[=] [Thread 2008] index: 0xa6b -> [func_data-0x118] = d[func_data-0x88] >> 0x8; 0x555f9370, rs: 0x555f93
[=] [Thread 2008] index: 0x2a -> b[[func_data-0x48] + 0x5] = b[func_data-0x118]; func_data-0x2ab, 0x93
[=] [Thread 2008] index: 0x2a -> b[[func_data-0x48] + 0x4] = b[func_data-0x88]; func_data-0x2ac, 0x70
[=] [Thread 2008] index: 0x2a -> b[[func_data-0x48] + 0x6] = b[func_data-0x120]; func_data-0x2aa, 0x5f
[=] [Thread 2008] index: 0x2a -> b[[func_data-0x48] + 0x7] = b[func_data-0x128]; func_data-0x2a9, 0x55
[=] [Thread 2008] index: 0xc2b -> [func_data-0x118] = [func_data-0x80] + [func_data-0x90]; 0xffffffffff971488, 0x555555f0abb0, rs: 0x55555587c038
[=] [Thread 2008] index: 0x38 -> [func_data-0x128] = [func_data-0x98] < 0x100; 0x0, rs: 0x1
# 加解密算法分析
观察 sub_F736C 返回前,所有 handler 的执行记录,主要分为四部分:
handler 执行过程.txt 已上传至附件,里面记录了整个执行流程。
# 环境初始化
虚拟栈的初始化已经 sub_F736C 的参数保存到虚拟栈:
[=] [Thread 2008] index: 0x9 -> [func_data-0x48] = [func_data-0x48] + 0xfea0; func_data-0x150, rs: func_data--0xfd50
//这里分号后面为自动生成的注释,表示从左到右,其内存的值。比如下面这一行,[func_data-0x48]的值是func_data-0x158;[func_data-0x38]的值是0。因为这是个写操作,就没有打印[[func_data-0x48]+0x158]的值了。
[=] [Thread 2008] index: 0x29 -> [[func_data-0x48]+0x158] = [func_data-0x38]; func_data-0x158, 0x0
[=] [Thread 2008] index: 0x29 -> [[func_data-0x48]+0x150] = [func_data-0x80]; func_data-0x160, 0x0
[=] [Thread 2008] index: 0x29 -> [[func_data-0x48]+0x148] = [func_data-0x88]; func_data-0x168, 0x0
[=] [Thread 2008] index: 0x29 -> [[func_data-0x48]+0x140] = [func_data-0x90]; func_data-0x170, 0x0
[=] [Thread 2008] index: 0x29 -> [[func_data-0x48]+0x138] = [func_data-0x98]; func_data-0x178, 0x0
[=] [Thread 2008] index: 0x29 -> [[func_data-0x48]+0x130] = [func_data-0xa0]; func_data-0x180, 0x0
[=] [Thread 2008] index: 0x29 -> [[func_data-0x48]+0x128] = [func_data-0xa8]; func_data-0x188, 0x0
[=] [Thread 2008] index: 0x29 -> [[func_data-0x48]+0x120] = [func_data-0xb0]; func_data-0x190, 0x0
[=] [Thread 2008] index: 0x3c -> [func_data-0xb0] = [[func_data-0x110] + 0x10]; func_data-0x450 -> func_data-0x440, 0x20
[=] [Thread 2008] index: 0x3c -> [func_data-0xa8] = [[func_data-0x110] + 0x8]; func_data-0x450 -> func_data-0x448, 0x100000
[=] [Thread 2008] index: 0x3c -> [func_data-0x90] = [[func_data-0x108] + 0x0]; 0x555555857110 -> 0x555555857110, 0x555555f0abb0
[=] [Thread 2008] index: 0x35 -> [func_data-0x88] = (signed )d[[func_data-0x110] + 0x0]; func_data-0x450, 0x555f9370
[=] [Thread 2008] index: 0x3c -> [func_data-0x128] = [[func_data-0x100] + 0x0]; 0x555555857118 -> 0x555555857118, 0x555555cd9eb0
[=] [Thread 2008] index: 0x2d -> [func_data-0x98] = d[func_data-0x130] + (int64)(int)0x0; 0x0, rs: 0x0
[=] [Thread 2008] index: 0x2a -> b[[func_data-0x48] + 0x110] = b[func_data-0x130]; func_data-0x1a0, 0x0
[=] [Thread 2008] index: 0x9 -> [func_data-0xa0] = [func_data-0x48] + 0x4; func_data-0x2b0, rs: func_data-0x2ac
[=] [Thread 2008] index: 0x29 -> [[func_data-0x48]+0x108] = [func_data-0xa0]; func_data-0x1a8, func_data-0x2ac
[=] [Thread 2008] index: 0x9 -> [func_data-0x120] = [func_data-0x130] + 0x4; 0x0, rs: 0x4
[=] [Thread 2008] index: 0x29 -> [[func_data-0x48]+0x118] = [func_data-0x120]; func_data-0x198, 0x4
[=] [Thread 2008] index: 0x1f -> [func_data-0x120] = int(0xff97 << 0x10)
[=] [Thread 2008] index: 0x1d -> [func_data-0x80] = [func_data-0x120] | 0x1488; 0xffffffffff970000, rs:0xffffffffff971488
[=] [Thread 2008] index: 0xc2b -> [func_data-0x110] = [func_data-0x80] + [func_data-0x128]; 0xffffffffff971488, 0x555555cd9eb0, rs: 0x55555564b338
[=] [Thread 2008] index: 0x92b -> [func_data-0x68] = [func_data-0x130] | [func_data-0xf8]; 0x0, 0x55555564b34c, rs: 0x55555564b34c
[=] [Thread 2008] index: 0xdeb -> [func_data-0x18] = [func_data-0x68]; 0x55555564b34c
[func_data-0x20] = 2
[func_data-0x38] = index_table_pointer+8; 0x5555557e5b90, rs: 0x5555557e5b98
[func_data-0x10] = index_table_pointer+8; 0x5555557e5b90, rs: 0x5555557e5b98
[=] [Thread 2008] index: 0x9 -> [func_data-0x108] = [func_data-0x48] + 0x108; func_data-0x2b0, rs: func_data-0x1a8
index_table_pointer = [func_data-0x18]; 0x55555564b34c
[func_data-0x20] = 0
[beg] = index_table_pointer
call func:(0x55555564b34c)([func_data-0x110], [func_data-0x108]); memset
index_table_pointer = [func_data-0x10]; 0x5555557e5b98
[beg] = index_table_pointer
# 准备一个 256 字节大小的 S-box 表
读取 [func_data-0x98] 的一个字节,赋值给 func_data-0x2a8 地址处,同时 [func_data-0x98] 和 [func_data-0x120] 都自增 1,直到 [func_data-0x98]==0x100。
[=] [Thread 2008] index: 0x2a -> b[[func_data-0x120] + 0x0] = b[func_data-0x98]; func_data-0x2a8, 0x0
[=] [Thread 2008] index: 0x2d -> [func_data-0x98] = d[func_data-0x98] + (int64)(int)0x1; 0x0, rs: 0x1
[=] [Thread 2008] index: 0x38 -> [func_data-0x128] = [func_data-0x98] < 0x100; 0x1, rs: 0x1
[=] [Thread 2008] index: 0x34 -> [func_data-0x130]; 0x0
[func_data-0x128]; 0x1
[func_data-0x18] = index_table_pointer+4+((int)(0xfffc << 0x10) >> 0xE); 0x5555557e5bd0
[func_data-0x20] = 2
[=] [Thread 2008] index: 0x9 -> [func_data-0x120] = [func_data-0x120] + 0x1; func_data-0x2a8, rs: func_data-0x2a7
index_table_pointer = [func_data-0x18]; 0x5555557e5bc4
[func_data-0x20] = 0
[beg] = index_table_pointer
[=] [Thread 2008] index: 0x2a -> b[[func_data-0x120] + 0x0] = b[func_data-0x98]; func_data-0x2a7, 0x1
[=] [Thread 2008] index: 0x2d -> [func_data-0x98] = d[func_data-0x98] + (int64)(int)0x1; 0x1, rs: 0x2
[=] [Thread 2008] index: 0x38 -> [func_data-0x128] = [func_data-0x98] < 0x100; 0x2, rs: 0x1
[=] [Thread 2008] index: 0x34 -> [func_data-0x130]; 0x0
[func_data-0x128]; 0x1
[func_data-0x18] = index_table_pointer+4+((int)(0xfffc << 0x10) >> 0xE); 0x5555557e5bd0
[func_data-0x20] = 2
[=] [Thread 2008] index: 0x9 -> [func_data-0x120] = [func_data-0x120] + 0x1; func_data-0x2a7, rs: func_data-0x2a6
index_table_pointer = [func_data-0x18]; 0x5555557e5bc4
[func_data-0x20] = 0
[beg] = index_table_pointer
[=] [Thread 2008] index: 0x2a -> b[[func_data-0x120] + 0x0] = b[func_data-0x98]; func_data-0x2a6, 0x2
[=] [Thread 2008] index: 0x2d -> [func_data-0x98] = d[func_data-0x98] + (int64)(int)0x1; 0x2, rs: 0x3
[=] [Thread 2008] index: 0x38 -> [func_data-0x128] = [func_data-0x98] < 0x100; 0x3, rs: 0x1
[=] [Thread 2008] index: 0x34 -> [func_data-0x130]; 0x0
[func_data-0x128]; 0x1
[func_data-0x18] = index_table_pointer+4+((int)(0xfffc << 0x10) >> 0xE); 0x5555557e5bd0
[func_data-0x20] = 2
[=] [Thread 2008] index: 0x9 -> [func_data-0x120] = [func_data-0x120] + 0x1; func_data-0x2a6, rs: func_data-0x2a5
index_table_pointer = [func_data-0x18]; 0x5555557e5bc4
[func_data-0x20] = 0
[beg] = index_table_pointer
以上逻辑用 C++ 实现如下:
#define SHUFFLE_TABLE_LEN 256 | |
unsigned char shuffle_table[SHUFFLE_TABLE_LEN] = { 0 }; | |
for (int i = 0; i < SHUFFLE_TABLE_LEN; ++i) | |
shuffle_table[i] = i; |
# S-box 表置换
遍历 S-box 表,i 从 0 自增到 255:
//读取S-box表的第i个元素 a
[=] [Thread 2008] index: 0x72b -> [func_data-0x128] = (int)d[func_data-0x120] >> 0x1f; 0x0
[=] [Thread 2008] index: 0xa6b -> [func_data-0xe0] = d[func_data-0x128] >> 0x1b; 0x0, rs: 0x0
[=] [Thread 2008] index: 0xcab -> [func_data-0xe0] = d[func_data-0xe0] + d[func_data-0x120]; 0x0, 0x0, rs: 0x0
[=] [Thread 2008] index: 0x9eb -> [func_data-0xe0] = [func_data-0x108] & [func_data-0xe0]; 0xffffffffffffffe0, 0x0, rs: 0x0
[=] [Thread 2008] index: 0xb2b -> [func_data-0xe0] = d[func_data-0x120] - d[func_data-0xe0]; 0x0, 0x0, rs: 0x0
[=] [Thread 2008] index: 0x4ab -> [func_data-0xe0] = d[func_data-0xe0] << 0x0; 0x0
[=] [Thread 2008] index: 0x9 -> [func_data-0xd8] = [func_data-0xf0] + 0x1; func_data-0x2a8, rs: func_data-0x2a7
[=] [Thread 2008] index: 0x30 -> [func_data-0xd0] = b[[func_data-0xf0] + 0x0]; func_data-0x2a8, 0x0
// S-box表的第i个元素和上一轮结果相加:a+last_result
// last_result初始化为0
[=] [Thread 2008] index: 0xcab -> [func_data-0xe8] = d[func_data-0xd0] + d[func_data-0xe8]; 0x0, 0x0, rs: 0x0
// [func_data-0x118]是sub_F736C函数的第3个参数,是一个0x20字节的数组,元素长度为1,这里命名为shuffle_factor_table。
// 从shuffle_factor_table取(i%0x20),然后与上一步相加:
// 得 a+last_result+shuffle_factor_table[i%0x20]
[=] [Thread 2008] index: 0x2d -> [func_data-0xc8] = d[func_data-0x120] + (int64)(int)0x1; 0x0, rs: 0x1
[=] [Thread 2008] index: 0xa6b -> [func_data-0x128] = d[func_data-0x128] >> 0x1e; 0x0, rs: 0x0
[=] [Thread 2008] index: 0xc2b -> [func_data-0xe0] = [func_data-0xe0] + [func_data-0x118]; 0x0, 0x55555587c038, rs: 0x55555587c038
[=] [Thread 2008] index: 0x30 -> [func_data-0xe0] = b[[func_data-0xe0] + 0x0]; 0x55555587c038, 0x48
[=] [Thread 2008] index: 0xcab -> [func_data-0xe8] = d[func_data-0xe0] + d[func_data-0xe8]; 0x48, 0x0, rs: 0x48
// tps_encrypt和tps_decrypt的第一个参数serino,小端序保存在内存中,然后取出一字节与上一步相加:
// 地 a+last_result+shuffle_factor_table[i%0x20]+serino[i%4]
[=] [Thread 2008] index: 0xcab -> [func_data-0x128] = d[func_data-0x128] + d[func_data-0x120]; 0x0, 0x0, rs: 0x0
[=] [Thread 2008] index: 0x9eb -> [func_data-0x128] = [func_data-0xf8] & [func_data-0x128]; 0xfffffffffffffffc, 0x0, rs: 0x0
[=] [Thread 2008] index: 0xb2b -> [func_data-0x128] = d[func_data-0x120] - d[func_data-0x128]; 0x0, 0x0, rs: 0x0
[=] [Thread 2008] index: 0x4ab -> [func_data-0x128] = d[func_data-0x128] << 0x0; 0x0
[=] [Thread 2008] index: 0xc2b -> [func_data-0x128] = [func_data-0x128] + [func_data-0xa0]; 0x0, func_data-0x2ac, rs: func_data-0x2ac
[=] [Thread 2008] index: 0x30 -> [func_data-0x128] = b[[func_data-0x128] + 0x0]; func_data-0x2ac, 0x70
[=] [Thread 2008] index: 0xcab -> [func_data-0x128] = d[func_data-0x128] + d[func_data-0xe8]; 0x70, 0x48, rs: 0xb8
// 上一步结果与0xFF求余
// 得 last_result = (a+last_result+shuffle_factor_table[i%0x20]+serino[i%4]) & 0xFF
[=] [Thread 2008] index: 0x72b -> [func_data-0x120] = (int)d[func_data-0x128] >> 0x1f; 0xb8
[=] [Thread 2008] index: 0xa6b -> [func_data-0x120] = d[func_data-0x120] >> 0x18; 0x0, rs: 0x0
[=] [Thread 2008] index: 0xcab -> [func_data-0x120] = d[func_data-0x120] + d[func_data-0x128]; 0x0, 0xb8, rs: 0xb8
[=] [Thread 2008] index: 0x9eb -> [func_data-0x120] = [func_data-0x100] & [func_data-0x120]; 0xffffffffffffff00, 0xb8, rs: 0x0
[=] [Thread 2008] index: 0xb2b -> [func_data-0xe8] = d[func_data-0x128] - d[func_data-0x120]; 0xb8, 0x0, rs: 0xb8
[=] [Thread 2008] index: 0x4ab -> [func_data-0x128] = d[func_data-0xe8] << 0x0; 0xb8
// S-box表置换
// tmp = S-box[i]
// S-box[i] = S-box[last_result]
// S-box[last_result] = tmp
[=] [Thread 2008] index: 0xc2b -> [func_data-0x128] = [func_data-0x128] + [func_data-0x110]; 0xb8, func_data-0x2a8, rs: func_data-0x1f0
[=] [Thread 2008] index: 0x30 -> [func_data-0x120] = b[[func_data-0x128] + 0x0]; func_data-0x1f0, 0xb8
[=] [Thread 2008] index: 0x2a -> b[[func_data-0xf0] + 0x0] = b[func_data-0x120]; func_data-0x2a8, 0xb8
[=] [Thread 2008] index: 0x2a -> b[[func_data-0x128] + 0x0] = b[func_data-0xd0]; func_data-0x1f0, 0x0
[=] [Thread 2008] index: 0x92b -> [func_data-0x120] = [func_data-0x130] | [func_data-0xc8]; 0x0, 0x1, rs: 0x1
// 没有遍历到0x256,回调到S-box置换的第一条指令,继续置换
[=] [Thread 2008] index: 0x38 -> [func_data-0x128] = [func_data-0x120] < 0x100; 0x1, rs: 0x1
[=] [Thread 2008] index: 0x34 -> [func_data-0x130]; 0x0
[func_data-0x128]; 0x1
[func_data-0x18] = index_table_pointer+4+((int)(0xffde << 0x10) >> 0xE); 0x5555557e5c80
[func_data-0x20] = 2
[=] [Thread 2008] index: 0x92b -> [func_data-0xf0] = [func_data-0x130] | [func_data-0xd8]; 0x0, 0x80000000db39, rs: func_data-0x2a7
index_table_pointer = [func_data-0x18]; 0x5555557e5bfc
[func_data-0x20] = 0
[beg] = index_table_pointer
以上逻辑用 C++ 实现如下:
void Fisher_Yates(unsigned char shuffle_table[SHUFFLE_TABLE_LEN], unsigned int serino) { | |
unsigned char shuffle_factor_table[SHUFFLE_FACTOR_TABLE_LEN] = { | |
0x48, 0xA9, 0xC8, 0x12, 0xCA, 0xFC, 0xD3, 0x5E, 0xB7, 0x61, 0x50, 0x17, 0x68, 0xBA, 0x7E, 0x2E, | |
0xB9, 0xA2, 0x38, 0x85, 0x35, 0x48, 0x55, 0x6C, 0x2C, 0x38, 0x43, 0x1F, 0x51, 0xD6, 0x30, 0x30 }; | |
unsigned char last_result = 0; | |
unsigned char serino_table[] = { serino & 0xFF, (serino >> 8) & 0xFF, (serino >> 16) & 0xFF, (serino >> 24) & 0xFF }; | |
for (int i = 0; i < SHUFFLE_TABLE_LEN; ++i) { | |
last_result = (shuffle_factor_table[i % SHUFFLE_FACTOR_TABLE_LEN] + shuffle_table[i] + last_result + serino_table[i % 4]) & 0xFF; | |
unsigned char tmp = shuffle_table[i]; | |
shuffle_table[i] = shuffle_table[last_result]; | |
shuffle_table[last_result] = tmp; | |
//printf("exchange: %x -> %x, factor: %x\n", i, last_result, shuffle_factor_table[i%SHUFFLE_FACTOR_TABLE_LEN]); | |
} | |
} |
# 数据加解密
遍历待加解密的数据,i 从 0 到 len (data)-1
// a = (i+1) & 0xFF
[=] [Thread 2008] index: 0x2d -> [func_data-0x128] = d[func_data-0x120] + (int64)(int)0x1; 0x100, rs: 0x101
[=] [Thread 2008] index: 0x72b -> [func_data-0x120] = (int)d[func_data-0x128] >> 0x1f; 0x101
[=] [Thread 2008] index: 0xa6b -> [func_data-0x120] = d[func_data-0x120] >> 0x18; 0x0, rs: 0x0
[=] [Thread 2008] index: 0xcab -> [func_data-0x120] = d[func_data-0x120] + d[func_data-0x128]; 0x0, 0x101, rs: 0x101
[=] [Thread 2008] index: 0x9eb -> [func_data-0x120] = [func_data-0x118] & [func_data-0x120]; 0xffffffffffffff00, 0x101, rs: 0x100
[=] [Thread 2008] index: 0xb2b -> [func_data-0x120] = d[func_data-0x128] - d[func_data-0x120]; 0x101, 0x100, rs: 0x1
[=] [Thread 2008] index: 0x4ab -> [func_data-0x128] = d[func_data-0x120] << 0x0; 0x1
// func_data-0xa8为待加解密的数据,这里命名为x
// 保存当前的字节x[i]到[func_data-0x100]
[=] [Thread 2008] index: 0x9 -> [func_data-0xf8] = [func_data-0x100] + 0x1; 0x0, rs: 0x1
[=] [Thread 2008] index: 0xc2b -> [func_data-0x100] = [func_data-0x100] + [func_data-0xa8]; 0x0, 0x100000, rs: 0x100000
// func_data-0x110保存着S-box的地址
// 从置换后的S-box取出一字节,index为a,并与上一轮结果相加
// 得b = S-box[a]+last_result
[=] [Thread 2008] index: 0xc2b -> [func_data-0x128] = [func_data-0x128] + [func_data-0x110]; 0x1, func_data-0x2a8, rs: func_data-0x2a7
[=] [Thread 2008] index: 0x30 -> [func_data-0xf0] = b[[func_data-0x128] + 0x0]; func_data-0x2a7, 0xa9
[=] [Thread 2008] index: 0xcab -> [func_data-0x108] = d[func_data-0xf0] + d[func_data-0x108]; 0xa9, 0x0, rs: 0xa9
[=] [Thread 2008] index: 0x72b -> [func_data-0xe8] = (int)d[func_data-0x108] >> 0x1f; 0xa9
[=] [Thread 2008] index: 0xa6b -> [func_data-0xe8] = d[func_data-0xe8] >> 0x18; 0x0, rs: 0x0
[=] [Thread 2008] index: 0xcab -> [func_data-0xe8] = d[func_data-0xe8] + d[func_data-0x108]; 0x0, 0xa9, rs: 0xa9
[=] [Thread 2008] index: 0x9eb -> [func_data-0xe8] = [func_data-0x118] & [func_data-0xe8]; 0xffffffffffffff00, 0xa9, rs: 0x0
[=] [Thread 2008] index: 0xb2b -> [func_data-0x108] = d[func_data-0x108] - d[func_data-0xe8]; 0xa9, 0x0, rs: 0xa9
[=] [Thread 2008] index: 0x4ab -> [func_data-0xe8] = d[func_data-0x108] << 0x0; 0xa9
// S-box表置换
// tmp = S-box[a]
// S-box[a] = S-box[b]
// S-box[b] = S-box[a]
[=] [Thread 2008] index: 0xc2b -> [func_data-0xe8] = [func_data-0xe8] + [func_data-0x110]; 0xa9, func_data-0x2a8, rs: func_data-0x1ff
[=] [Thread 2008] index: 0x30 -> [func_data-0xe0] = b[[func_data-0xe8] + 0x0]; func_data-0x1ff, 0xc1
[=] [Thread 2008] index: 0x2a -> b[[func_data-0x128] + 0x0] = b[func_data-0xe0]; func_data-0x2a7, 0xc1
[=] [Thread 2008] index: 0x2a -> b[[func_data-0xe8] + 0x0] = b[func_data-0xf0]; func_data-0x1ff, 0xa9
// x[i] = x[i] ^ ((S-box[a] + tmp) & 0xFF)
[=] [Thread 2008] index: 0x30 -> [func_data-0x128] = b[[func_data-0x128] + 0x0]; func_data-0x2a7, 0xc1
[=] [Thread 2008] index: 0xcab -> [func_data-0x128] = d[func_data-0xf0] + d[func_data-0x128]; 0xa9, 0xc1, rs: 0x16a
[=] [Thread 2008] index: 0x30 -> [func_data-0xf0] = b[[func_data-0x100] + 0x0]; 0x100000, 0x12
[=] [Thread 2008] index: 0x37 -> [func_data-0x128] = [func_data-0x128] & 0xff; 0x16a, rs:0x6a
[=] [Thread 2008] index: 0x7 -> [func_data-0x128] = ((1(LL) << (W10+1)) - 1) & ([func_data-0x128] >> W11); 0x1f, 0x6a, 0x0, rs: 0x6a
[=] [Thread 2008] index: 0xc2b -> [func_data-0x128] = [func_data-0x128] + [func_data-0x110]; 0x6a, func_data-0x2a8, rs: func_data-0x23e
[=] [Thread 2008] index: 0x30 -> [func_data-0x128] = b[[func_data-0x128] + 0x0]; func_data-0x23e, 0xef
[=] [Thread 2008] index: 0x36b -> [func_data-0x128] = [func_data-0x128] ^ [func_data-0xf0]; 0xef, 0x12, rs: 0xfd
[=] [Thread 2008] index: 0x2a -> b[[func_data-0x100] + 0x0] = b[func_data-0x128]; 0x100000, 0xfd
// 没有遍历到x的长度,继续遍历
[=] [Thread 2008] index: 0x92b -> [func_data-0x100] = [func_data-0x130] | [func_data-0xf8]; 0x0, 0x1, rs: 0x1
[=] [Thread 2008] index: 0x1eb -> base_W9_value < base_W8_value: [func_data-0x128] = 1; w8=[func_data-0xb0]=32, w9=[func_data-0x100]=1
[=] [Thread 2008] index: 0x34 -> [func_data-0x130]; 0x0
[func_data-0x128]; 0x1
[func_data-0x18] = index_table_pointer+4+((int)(0xffde << 0x10) >> 0xE); 0x5555557e5d24
[func_data-0x20] = 2
[=] [Thread 2008] index: 0x4ab -> [func_data-0x130] = d[func_data-0x130] << 0x0; 0x0
index_table_pointer = [func_data-0x18]; 0x5555557e5ca0
[func_data-0x20] = 0
[beg] = index_table_pointer
以上逻辑用 C++ 实现如下:
void encrypt_and_decrypt_data(unsigned char shuffle_table[SHUFFLE_TABLE_LEN], unsigned char* x, int len) { | |
unsigned char last_result = 0; | |
for (int i = 0; i < len; ++i) { | |
int s_i = (i + 1) & 0xFF; | |
unsigned char cur = shuffle_table[s_i]; | |
// last_result = (last_result + cur) & 0xFF; | |
last_result += cur; // no need to 'and 0xFF', because the type of last_result is unsigned char | |
shuffle_table[s_i] = shuffle_table[last_result]; | |
shuffle_table[last_result] = cur; | |
unsigned char tmp = (cur + shuffle_table[s_i]) & 0xFF; | |
x[i] = x[i] ^ shuffle_table[tmp]; | |
} | |
} |
# 总结
第一次使用 qiling 来做模拟执行,踩了不少坑。不过这些坑填完了,之后模拟执行就会方便很多。
libxx.so 的加解密算法很简单,相信大家已经能看出来这个是 RC4,不过稍微有一点魔改,把密钥分成了两部分。
加解密算法的保护主要还是通过虚拟机来实现的,其中也有一点花指令和动态字符串解密,不过这些在 libxx.so 里都很简单,所以没有细说。
希望本文可以给想用 qiling 做模拟执行的朋友一些提示,快速过掉 qiling 的一些坑。
